- Produkte
- UNSERE PLATFORM
 The Panzura Data Management PlatformModernisieren Sie Ihre Speicherinfrastruktur für Dateidaten und verbessern Sie die Sicherheit.
The Panzura Data Management PlatformModernisieren Sie Ihre Speicherinfrastruktur für Dateidaten und verbessern Sie die Sicherheit.
-
Discover why modern data leaders prefer the Panzura Data Management Platform
- UNSERE PRODUKTE UND ANGEBOTE
 Panzura CloudFSVereinfachen und sichern Sie Ihre Datenspeicherung mit einer einzigen maßgeblichen Quelle.
Panzura CloudFSVereinfachen und sichern Sie Ihre Datenspeicherung mit einer einzigen maßgeblichen Quelle. Panzura Erkennen und RettenMehr Sicherheit vor Ransomware durch aktive Erkennung und Warnungen sowie Experten-Support.
Panzura Erkennen und RettenMehr Sicherheit vor Ransomware durch aktive Erkennung und Warnungen sowie Experten-Support. Panzura Data ServicesErhalten Sie Transparenz, Governance und Analysen in einem einheitlichen SaaS-Dashboard.
Panzura Data ServicesErhalten Sie Transparenz, Governance und Analysen in einem einheitlichen SaaS-Dashboard. Panzura KanteVerbessern Sie den Datenzugriff und fördern Sie die Zusammenarbeit mit integrierten Tools.
Panzura KanteVerbessern Sie den Datenzugriff und fördern Sie die Zusammenarbeit mit integrierten Tools.
- Lösungen
- LÖSUNGEN
- Bankwesen, Finanzdienstleistungen und VersicherungenFinanzielle Wertschöpfung durch digitale Transformation
- Architektur, Ingenieurwesen und BauwesenVerbesserung der Time-to-Value durch Datensicherung und Verbesserung der standortübergreifenden Zusammenarbeit
- Gesundheitswesen und BiowissenschaftenSchutz von Patientendaten, Verbesserung der Ergebnisse und Unterstützung der Forschung
- Medien und UnterhaltungSichere globale Zusammenarbeit und Reduzierung des exponentiellen Datenwachstums
- HerstellungStraffung der Arbeitsabläufe und Verbesserung der Effizienz, um die Markteinführung zu beschleunigen
- Öffentlicher SektorBietet Sicherheit auf militärischem Niveau und ermöglicht erweiterte Datenkonformität
- Ressourcen
- Unterstützung
- KUNDENBETREUUNG
- Globale DienstleistungenProfitieren Sie von einer optimierten Datenmigration und einem erstklassigen Kundenservice.
- Service-DrehscheibeSie verdienen den besten Service, den die Branche zu bieten hat. Holen Sie ihn sich hier.
- WissensdatenbankErfahren Sie alles, was Sie über die Produkte und Dienstleistungen von Panzura wissen müssen.
- Partner-PortalZugriff auf Tools und Ressourcen, die exklusiv für unsere Vertriebspartner entwickelt wurden.
- Informationen zur Unterstützungsupport@panzura.com
- Über
- ÜBER PANZURA
- Unser UnternehmenWir haben einen neuen Weg an die Spitze eingeschlagen - und es ist eine Wahnsinnsgeschichte!
- FührungsteamTreffen Sie Querdenker, Motivatoren und Vordenker, die unseren Erfolg vorantreiben.
- KarriereWir suchen die Besten und Intelligentesten. Wenn Sie das sind, lassen Sie es uns wissen.
- PresseraumBleiben Sie auf dem Laufenden mit unseren neuesten Nachrichten, Einblicken und Unternehmens-Updates.
Weiße Papiere
Panzura CloudFS 8
CloudFS verwandelt komplexe, aus mehreren Komponenten bestehende und häufig von mehreren Anbietern betriebene Umgebungen in eine vereinfachte Datenverwaltungslösung und trägt gleichzeitig zur Kostensenkung, Risikominderung und Verringerung der betrieblichen Komplexität bei.

Der Network-Attached-Storage, der seit fast drei Jahrzehnten die Hauptstütze der Datenspeicherung ist, kämpft damit, mit den eskalierenden Speichermengen fertig zu werden. Er ist auch nicht in der Lage, Dateien standortübergreifend innerhalb eines Zeitrahmens konsistent zu machen, der es Teams ermöglicht, produktiv zu arbeiten. NAS ist äußerst leistungsfähig, wenn es sich in der Nähe der Benutzer befindet, die auf die gespeicherten Dateien zugreifen, wird aber untragbar langsam, wenn Benutzer von außerhalb darauf zugreifen.
Infolgedessen setzen Unternehmen an jedem Standort einzelne NAS-Instanzen ein, wodurch unzusammenhängende Speicherinseln entstehen, die eine erhebliche Menge an Datenduplikaten enthalten. Um die Konsistenz von Dateien über verschiedene Standorte hinweg zu gewährleisten, ist eine planmäßige Datenreplikation erforderlich, sofern sie überhaupt versucht wird, und die Daten müssen repliziert werden, um ein akzeptables Maß an Haltbarkeit zu erreichen. In der Regel bedeutet dies, dass mindestens ein zweiter Datensatz für die Sicherung und ein dritter für die Wiederherstellung im Notfall vorhanden sein muss.
Dies trägt zum exponentiellen Wachstum unstrukturierter Daten bei und verursacht Komplexität und Kosten für IT-Teams, die mit der mangelnden Übersicht über ihre zahlreichen Datennetze zu kämpfen haben. Dieser veraltete Ansatz zur Datenspeicherung bietet keine einfache Möglichkeit, granulare Datenmengen im Falle eines Verlusts wiederherzustellen, und macht die Daten anfällig für Ransomware und andere Malware-Angriffe.
CloudFS verwandelt komplexe, aus mehreren Komponenten bestehende und häufig von mehreren Anbietern betriebene Umgebungen in eine vereinfachte Datenverwaltungslösung und trägt gleichzeitig zur Kostensenkung, Risikominderung und Verringerung der betrieblichen Komplexität bei.
Panzura's global cloud file system CloudFS provides a single authoritative data set held in cloud object storage, with immediate global data consistency and local-feeling file performance across all locations. Data from all legacy storage instances is consolidated, de-duped and compressed, significantly reducing the overall unstructured data footprint.
Die Kompatibilität mit einer breiten Palette von Objektspeichern bietet die Flexibilität, öffentliche Cloud-Speicher wie AWS S3 und Azure Blob oder private Objektspeicher wie IBM iCOS und Cloudian zu nutzen.
Mit der Datenbeständigkeit ohne Replikation*, der granularen Möglichkeit, Daten zu einem bestimmten Zeitpunkt wiederherzustellen, und der Widerstandsfähigkeit gegen Ransomware ersetzt die Lösung Panzura nicht nur den netzwerkgebundenen Speicher, sondern auch die damit verbundenen Backup- und Offsite-DR-Prozesse und Speicher. Sie bietet auch eine zentrale Suche und Überwachung des gesamten Dateinetzwerks.
Panzura CloudFS™.
PanzuraDas globale Cloud-Dateisystem CloudFS ist ein verteiltes Dateisystem mit Netzwerkbeschleunigungstechnologie, das speziell für hoch latente Remote-Objektspeicher entwickelt wurde und in der Lage ist, die Einschränkungen zu überwinden, die Unternehmen daran hindern, Cloud-Speicher erfolgreich in ihre Infrastruktur zu integrieren.
Das Ergebnis ist eine Multi-Cloud-Plattform für Dateidienste, die hochleistungsfähiges Tiered NAS, globale Dateizusammenarbeit, Ransomware-Schutz, aktive Archivierung, Backup und DR an allen Standorten eines Unternehmens ermöglicht.
Dateibasierte Speicherung
Panzura hat eine hochleistungsfähige, dateibasierte, globale Speicherplattform für die Cloud entwickelt, um die 80 % der derzeitigen unstrukturierten Daten zu bewältigen. Durch die Unterstützung von NFS- und SMB-Übertragungsprotokollen, die von den meisten Anwendungen verwendet werden, kann Panzura ohne Änderungen in bestehende IT-Infrastrukturen integriert und mit allen wichtigen Cloud-Speicherplattformen verbunden werden, was die Bereitstellung vereinfacht und die Auswirkungen auf den Betrieb minimiert. Alle Daten werden in einem einzigen globalen Dateisystem verwaltet, was die Benutzerinteraktion und die Systemadministration vereinfacht, während sie in Unternehmensanwendungen eingebunden werden und sowohl auf lokale Festplatten als auch auf die Cloud ausgerichtet sind.
Cloud-Objektspeicher
Bei der Objektspeicherung, dem typischen Speichersystem in der Cloud, werden die Daten aufgeteilt und als Container oder Chunks flexibler Größe gespeichert. Jedes Chunk kann individuell adressiert, manipuliert und an vielen Orten gespeichert werden - nicht an eine bestimmte Festplatte gebunden - mit einigen zugehörigen Metadaten.
Objektspeicher können auf Milliarden von Objekten und Exabytes an Kapazität skaliert werden und schützen die Daten effektiver als RAID. Aufgrund der diskreten Scale-Out-Architektur der Objektspeicherung haben Laufwerksausfälle nur geringe Auswirkungen auf die Daten, und selbstheilende Replikationsfunktionen sorgen für eine sehr schnelle Wiederherstellung (man denke nur an Wochen bei alten RAID-Systemen mit großer Kapazität). Diese Kombination aus Skalierbarkeit und Robustheit macht Objektspeicher zu einem idealen Ziel für die Lagerung von Daten.
CloudFS verfügt über eine direkte Schnittstelle zu allen wichtigen Objektspeicher-APIs und zugehörigen Speicherebenen und nutzt objektbasierten Cloud-Speicher als Data Warehouse, um Skalierbarkeit und Verfügbarkeit mit einer überzeugenden Kostenstruktur zu bieten.
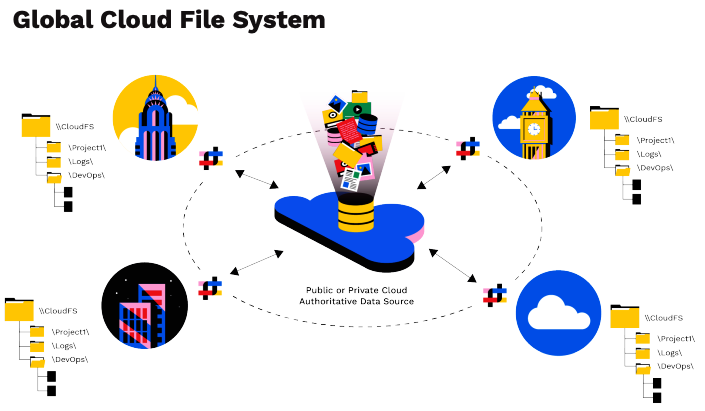
Das Herzstück eines jeden Speichersystems für unstrukturierte Daten ist das Dateisystem. Panzura CloudFS wurde entwickelt, um die Nutzung und Speicherung von Dateien genau zu verwalten und eine nahtlose, leistungsstarke und robuste Multi-Cloud-Datenverwaltung zu ermöglichen. Es verbessert WAFL und ZFS und integriert Cloud-Speicher als native Funktion. Jeder Benutzer kann an jedem Ort und zu jeder Zeit Dateien anzeigen und darauf zugreifen, die von einem anderen Benutzer erstellt wurden.
Das Dateisystem koordiniert dynamisch, wo Dateien gespeichert werden, was an die Cloud gesendet wird, wer Bearbeitungs- und Zugriffsrechte hat, welche Dateien zur Verbesserung der Leistung lokal zwischengespeichert werden und wie Daten, Metadaten und Snapshots verwaltet werden. Die Struktur des Dateisystems hat keine praktische Begrenzung für die Anzahl der vom Benutzer verwalteten Snapshots pro CloudFS.
Panzura’s innovative use of metadata and snapshots for file system updates, combined with unique caching and pinning capabilities in the Panzura nodes—virtualized edge appliances deployed either locally or in the cloud—allows you to view data and interact through an enterprise-wide file system that is continually updated in real time. Support for extended file system access control lists (ACLs) empowers administrators to set file access and management policies on a per user basis.
Global Namespace
The Panzura global namespace is an in-band file system fabric that integrates multiple physical file systems into a single space and is mounted locally on each node. The entire global namespace has the root label of the distributed cloud file system.
Die folgenden zwei globalen Namensraumpfade verweisen beispielsweise auf dasselbe Verzeichnis (\projects\team20) und sind sowohl von beiden Knoten als auch lokal auf den Knoten cc1-ln (London) und cc1-ny (New York) sichtbar.
CloudFS wurde entwickelt, um die sofortige Datenintegrität an allen Standorten innerhalb des Dateisystems zu gewährleisten, unabhängig von der Anzahl der Standorte und der Entfernung zwischen ihnen. Dies erfordert die Einhaltung von zwei grundlegenden Prinzipien:
- Nur ein Benutzer kann dieselbe Datei - oder, wenn Anwendungen Byte-Bereichs- oder Element-Sperren unterstützen, denselben Teil einer Datei - zu jeder Zeit bearbeiten. Wenn ein anderer Benutzer versucht, eine Datei zu öffnen oder auf einen Teil einer Datei zuzugreifen, die für die Bearbeitung gesperrt ist, wird er darüber informiert, dass die Datei gesperrt ist, oder er kann das Dateielement nicht bearbeiten.
- Wenn ein Benutzer eine Datei mit Lese- und Schreibzugriff öffnet, sieht er die zuletzt gespeicherten Änderungen an dieser Datei, unabhängig davon, wie lange diese Änderungen zurückliegen und wo der Benutzer sie vorgenommen hat.
Um dies zu erreichen, entkoppelt Panzura die Daten von den Metadaten und integriert den globalen Namespace in die Metadaten.
Metadata is stored centrally in the cloud for durability in addition to being fully cached locally for enhanced performance. All nodes in a single namespace or CloudFS synchronize metadata updates simultaneously every 60 seconds in a hub (cloud) and spoke (node) configuration. This is further complemented by a peer to peer (mesh) synchronization event that occurs in real-time when lock dynamically moves from one node to another through the distributed global file locking.
Panzura Snapshots für sofortige globale Dateikonsistenz
Schnappschüsse für Konsistenz
Snapshots capture the state of a file system at a given point in time. For example, if blocks A, B, and C of a file are written and snapshot 1 is taken, that snapshot captures blocks A, B, and C to represent the file.
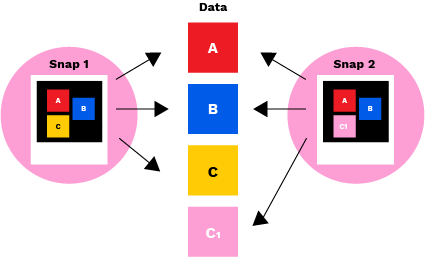
Wenn dann jemand die Datei so bearbeitet, dass Block C1 C ersetzt und Schnappschuss 2 gemacht wird, zeigen die Datenzeiger in den Blöcken A, B und C der Schnappschussdatei jetzt auf A, B und C1. Der Block C bleibt erhalten, wird aber in Snapshot 2 nicht referenziert. Wenn Sie den ursprünglichen Zustand wiederherstellen möchten, können Sie Snapshot 1 wiederherstellen, dann zeigt das System wieder auf A, B und C, ignoriert aber C1. Durch die Verwendung von Snapshots zur Erstellung und Speicherung einer fortlaufenden Reihe von Wiederherstellungspunkten für verschiedene Phasen der Datenlebensdauer kann im Falle eines Datenverlusts oder einer Beschädigung immer ein konsistenter Zustand des Dateisystems wiederhergestellt werden.
Schnappschüsse für Währung
Panzura nutzt die Unterschiede zwischen aufeinanderfolgenden Schnappschüssen, um die Konsistenz des Dateisystems aufrechtzuerhalten und um die Daten im Dateisystem zu schützen. In einem Prozess, der Synchronisierung genannt wird, nimmt das Panzura Dateisystem die Nettoänderungen an Metadaten und Daten zwischen aufeinanderfolgenden Snapshots und sendet sie an die Cloud. Der Metadatenanteil dieser Änderungen wird von allen anderen Panzura -Knoten im konfigurierten CloudFS aus der Cloud abgerufen, wo sie zur Aktualisierung des Dateisystemstatus und zur Aufrechterhaltung der Aktualität verwendet werden (siehe Abbildung unten).
Diese Systemaktualisierung erfolgt kontinuierlich über alle Knoten hinweg, wobei jeder Knoten extrem kleine Metadaten-Snapshot-Deltas in einer Hub-and-Spoke-Konfiguration an die Cloud sendet und von dort empfängt und sie zur nahtlosen und transparenten Aktualisierung des Dateisystems verwendet.
Zum Beispiel nimmt ein Knoten in London (blau in der Abbildung unten) Snap 1 und später Snap 2 auf. Der Unterschied in den Metadaten zwischen Snap 1 und Snap 2 für London wird in blau als 1-2Meta angezeigt. Der Unterschied in den Daten zwischen Snap1 und Snap2 für London wird in blau als 1-2Data dargestellt. London sendet seine 1-2Meta und 1-2Data, um die Cloud zu aktualisieren, ebenso wie alle anderen Knoten in der Infrastruktur. London erhält auch Metadaten-Updates für alle anderen Knoten zurück (als 1-2Meta in rosa für New York und in rot für Las Vegas dargestellt).
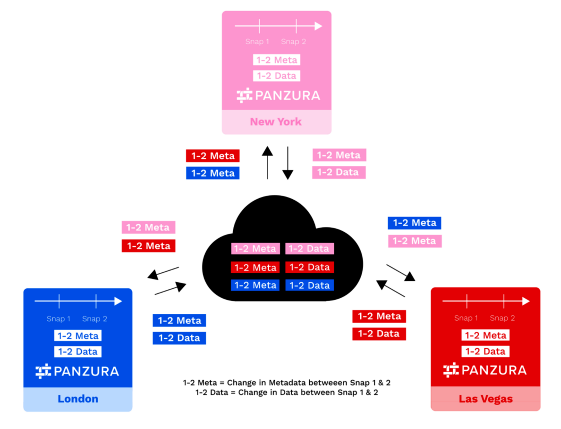
Alle Änderungen an Daten und Metadaten werden gespeichert und zeitlich nacheinander verfolgt.
Sollte es zu einem Datenverlust oder einer Datenbeschädigung am lokalen Knoten oder in der Cloud kommen, können die Daten in jedem früheren Zustand, in dem ein Snapshot erstellt wurde, wiederhergestellt werden, ohne dass ein separater Sicherungsprozess erforderlich ist.
Es ist wichtig, noch einmal darauf hinzuweisen, dass die Größe dieser Snapshot-Deltas (1-2Meta, 1-2Data) im Verhältnis zu den Daten im Dateisystem außerordentlich gering ist; daher können sie kontinuierlich erfasst werden und Bandbreite und Kapazität sehr effizient nutzen.
Das Ergebnis ist der Heilige Gral eines globalen Dateisystems: eine Lösung, die fast keinen Overhead erfordert und nahezu in Echtzeit kontinuierliche, schnelle Aktualisierungen über alle Standorte hinweg ermöglicht.
Schnappschüsse für mehr Effizienz
Panzura Knoten haben keine praktische Begrenzung für benutzerverwaltete Snapshots. Mit dieser Kategorie von Snapshots können Benutzer Daten ohne Eingreifen der IT-Abteilung wiederherstellen, indem sie einfach den gewünschten Snapshot in ihrem Inventar suchen und ihn wiederherstellen. Die Richtlinien für benutzerverwaltete Snapshots (Häufigkeit, Alter usw.) werden von der IT-Verwaltung festgelegt. Ein Beispiel: Ein Microsoft Windows-Benutzer in New York reist nach London und stellt fest, dass er eine Datei benötigt, die er vor 3 Monaten gelöscht hat. Sie steuert ihren Windows Explorer zum lokalen Londoner Panzura Knoten, navigiert zu ihrem Snapshot-Ordner und findet das Datum/die Uhrzeit, das/die der Dateisystemansicht entspricht, die die Datei enthält, die sie wiederherstellen möchte. Sie öffnet diesen Snapshot, navigiert zu der Datei oder den Dateien, die sie wiederherstellen möchte, und zieht die benötigte(n) Datei(en) einfach per Drag & Drop an den aktuellen Speicherort im Dateisystem, an dem sie wiederhergestellt werden soll. Innerhalb weniger Minuten hat sie die benötigten Dateien wiederhergestellt und kann mit ihrer Arbeit fortfahren, ohne jemanden aus der IT-Abteilung hinzuzuziehen.
Zur Vereinfachung der Nutzung wurden Benutzer-Snapshots in die Funktion "Vorherige Version" von Windows integriert, so dass die Benutzer mit der rechten Maustaste auf eine beliebige Datei oder einen beliebigen Ordner klicken und problemlos einen früheren Snapshot wiederherstellen können. Die IT-Administration kann die Snapshot-Richtlinien bei Bedarf dynamisch ändern, um Datenaufbewahrungsrichtlinien zu erfüllen und Häufigkeit und Dauer für eine optimale Systemleistung und Benutzerzufriedenheit auszugleichen.
Schnappschüsse Vorteile
Panzura Snapshot-Technologie bietet drei wesentliche Vorteile für das globale Dateisystem: Konsistenz, Aktualität und Effizienz. Kontinuierliche Snapshots bieten granulare Wiederherstellungspunkte, so dass im Falle eines Datenverlusts ein konsistenter Dateisystemzustand mit minimaler Unterbrechung oder Verzögerung wiederhergestellt werden kann.
Panzura Snapshot-Technologie bietet allen Nutzern an allen Standorten einen aktuellen Überblick über das gesamte Dateisystem. Dies geschieht durch die globale Synchronisierung aller Dateisystemansichten in Echtzeit, so dass die Benutzer den Cloud-Speicher so erleben können, als wäre er lokal, wodurch das Haupthindernis für ein wirklich globales Dateisystem beseitigt wird.
Die Panzura Snapshot-Technologie ermöglicht es den Nutzern, ihre Daten bei Bedarf selbst wiederherzustellen und entlastet damit einen wichtigen Aspekt des Nutzersupports, so dass mehr Zeit für strategische IT-Projekte zur Verfügung steht. Der Panzura Knoten bringt die Leistung der Cloud in Unternehmen, ohne die Benutzererfahrung zu beeinträchtigen.
Intelligente Zwischenspeicherung am Rande des Netzes für eine lokal spürbare Leistung
SmartCache
Panzura CloudFS nutzt einen benutzerdefinierten Prozentsatz des lokalen Speichers als SmartCache, um auf intelligente Weise heiße, warme und kalte Dateiblockstrukturen zu verfolgen, wenn auf sie zugegriffen wird. Diese Form der Zwischenspeicherung erhöht die E/A-Leistung von Lesevorgängen erheblich (und senkt die Gebühren für den Zugriff auf den Cloud-Objektspeicher), indem sie aus dem lokalen Zwischenspeicher (sowohl im Arbeitsspeicher als auch im persistenten lokalen Flash-Speicher) und nicht aus dem externen Cloud-Speicher bedient werden. Das Dateisystem puffert auch Schwankungen in der Cloud-Verfügbarkeit, um konsistente Lese-/Schreib-Antwortzeiten aufrechtzuerhalten - Leistung UND Verfügbarkeit am Rande.
Caching-Richtlinien bieten zwei grundlegende Funktionen. Die erste Funktion ist das Anheften von Daten, bei dem Daten mithilfe flexibler Platzhalterregeln auf dem lokalen Speicher verfügbar gehalten werden. Pinning ist eine erzwungene Aktion und wird für vollständige Dateien ausgeführt, während SmartCache eine lesestimulierte Aktion ist, die für häufig genutzte Blöcke innerhalb einer Datei ausgeführt wird.
Das Anheften von Daten führt zu einer 100-prozentigen lokalen Lesegarantie, während SmartCache auf der Grundlage früherer E/A-Lesemuster innerhalb des lokalen Knotens deterministisch ist. Die zweite Funktion der Caching-Richtlinien ist das Auto-Caching, bei dem Daten automatisch auf der Grundlage definierter Regeln lokal zwischengespeichert werden. Automatisch zwischengespeicherte Daten können jedoch bei Bedarf für angeforderte heiße Daten wieder entfernt werden.
Die angehefteten oder automatisch zwischengespeicherten Daten sind eine Teilmenge der gesamten SmartCache-Speicherebene. Angepinnte Daten gelten als zwischengespeicherte Daten mit hoher Priorität, die nur mit Genehmigung des Administrators entfernt werden, während automatisch zwischengespeicherte Daten (basierend auf Platzhalterregeln) oder SmartCache-Daten (automatisch zwischengespeicherte Datenblöcke basierend auf beobachteten Nutzungsmustern) bei Bedarf vom System entfernt werden können, um Platz für Daten zu schaffen, auf die häufiger zugegriffen wird. Das Gleichgewicht zwischen Pinning und SmartCache ist heikel, da eine Pinning-Regel die logische Platzierung von Datenblöcken im SmartCache erzwingt, wodurch lokaler Speicherplatz verbraucht wird, was sich auf die lokale Cache-Auslastung und -Effizienz auf eine Weise auswirken kann, die der Administrator möglicherweise nicht bedacht hat. Da Pinning-Richtlinien höchste Priorität haben und Caching-Regeln, die auf beobachtetem Verhalten beruhen, außer Kraft setzen, sollten diese Richtlinien sorgfältig beachtet werden, damit nicht der gesamte lokale Speicher verbraucht wird und nur wenig Platz für tatsächliche heiße Daten bleibt.
Die Funktion "Auto Pre-populate" bietet ein noch höheres Maß an automatisierten Caching-Funktionen. Wenn diese Funktion aktiviert ist, speichert der Knoten automatisch Dateien vor, wenn sich die Eigentumsverhältnisse zwischen den Knoten in einem CloudFS ändern. Dies ist besonders hilfreich bei kollaborativen Workflows, bei denen Benutzer an verschiedenen Standorten an denselben Datensätzen arbeiten. Wenn der Knoten Eigentümerwechsel zwischen den Standorten feststellt, werden die Daten im selben Verzeichnis automatisch zwischengespeichert, um Leseanforderungen der Benutzer für diese Dateien zwischen den Standorten vorwegzunehmen.
Lokale Speichernutzung
Ein Teil des lokalen Speichers wird für den SmartCache reserviert. Dieser Anteil ist konfigurierbar und wird standardmäßig auf 50 % festgelegt. Im Laufe der Zeit und durch die allgemeine Nutzung füllt das System den lokalen Cache dynamisch mit heißen Datenblöcken aus allen Dateien, die von Benutzern und Anwendungen gelesen werden. Die optimalste und effizienteste SmartCache-Konfiguration besteht darin, dass der größte Teil des Cache aus heißen und warmen Blöcken besteht, wobei die meisten kalten Blöcke in die Cloud ausgelagert werden. In diesem Fall wird ein hoher Prozentsatz der Lesevorgänge direkt aus dem lokalen Cache und nicht aus der Cloud abgewickelt. Dies ist der optimale Cache-Zustand, der jedoch schwieriger zu erreichen ist, wenn mehr Pinning-Regeln hinzugefügt werden.
Blöcke, die sich im lokalen Cache befinden, sind durch eine Kombination von 3 verschiedenen Temperaturzuständen, 2 Änderungszuständen und 2 Schutzzuständen gekennzeichnet. Diese sind:
Pinned-Blocks, die gepinnt wurden, erhalten die höchste Priorität im SmartCache und werden als letzte entfernt, aber nur, wenn kritischer Schreibraum benötigt wird.
Hot-Blocks, auf die häufig zum Lesen zugegriffen wird (von 0-7 Tagen).
Ziel ist es, die meisten heißen Blöcke im lokalen Cache zu haben.
Warm-Blöcke, die kürzlich heiß waren, aber noch nicht so lange gelesen wurden wie die heißen Blöcke (8-30 Tage). Sie werden nach den kalten, aber vor den heißen Blöcken entfernt, wenn zusätzliche
SmartCache-Speicherplatz wird benötigt.
Cold-Blöcke, auf die seit 30 Tagen oder länger nicht mehr zugegriffen wurde. Dies sind die ersten Blöcke, die entfernt werden, wenn SmartCache Platz für angeheftete, heiße oder warme Blöcke benötigt. Dort
sollte immer einige kalte Blöcke enthalten, da dies bedeutet, dass der SmartCache alle gepinnten, heißen und warmen Blöcke vollständig enthält.
Kürzlich geänderte Blöcke - Blöcke, in die im Rahmen von Aktualisierungen einer Datei geschrieben wurde.
Nicht geändert - Sperren, die nicht geschrieben wurden.
Geschützt in der Cloud - Blöcke, die erfolgreich in den Cloud-Speicher hochgeladen wurden.
Noch nicht Cloud-geschützt - Sperren, die noch nicht in die Cloud hochgeladen wurden.
Pinning verbraucht SmartCache-Speicherplatz, indem vollständige Dateien in den lokalen Cache gezwungen werden. Der Administrator kann die automatische Cache-Logik des SmartCache außer Kraft setzen, um das Auslagern bestimmter Blöcke auf unbestimmte Zeit zu deaktivieren und so die Anforderungen der Benutzer oder der Website zu erfüllen.
Aus diesem Grund sollten bestimmte angeheftete Regeln sorgfältig beachtet werden, um zu verhindern, dass eine Regel zu einer Überlastung des lokalen Cache-Speicherplatzes führt (rotierende Verdrängung von Daten mit neuen Daten aufgrund einer reduzierten Cache-Kapazität). Es wird empfohlen, dass Administratoren die Auto-Caching-Aktion nutzen oder die Funktion "Auto Pre-populate" aktivieren, wenn dies möglich ist. Panzura CloudFS ist so konzipiert, dass alle Daten so schnell wie möglich in die Cloud übertragen werden. Die Daten werden immer in die Cloud übertragen und hochgeladen, bevor sie heiß, warm oder kalt werden, basierend auf den jüngsten Leseaktivitäten.
Wenn Daten gepinnt werden, werden diese Daten nur dann aus dem SmartCache entfernt, wenn der Administrator die Pinning-Richtlinie ändert oder Platz für Schreibvorgänge benötigt wird und alle anderen heißen, warmen und kalten Daten entfernt wurden.
Angepinnte Daten werden als Cache-Daten mit hoher Priorität betrachtet. Umgekehrt werden automatisch gecachte SmartCache-Daten als Cache-Daten mit niedriger Priorität behandelt, die vom System automatisch gelöscht werden können, wenn SmartCache-Speicherplatz für neue heiße Daten benötigt wird. Je mehr angeheftete Daten den IRC verbrauchen, desto geringer wird die nutzbare Kapazität des automatischen Caches. Dies wirkt sich negativ auf die am häufigsten gelesenen Daten aus, da sie verdrängt und dann ständig neu gelesen werden müssen. Daher sollten aggressive Richtlinien, die große Datenmengen anpinnen, nur sparsam eingesetzt werden, da dies zu übermäßiger lokaler Festplatten-E/A führen und die Leistung verringern kann.
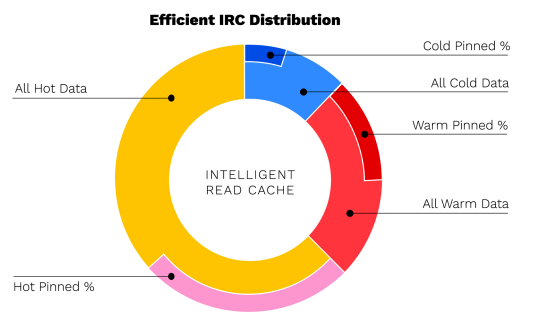
Im Idealfall sollten sich die meisten Daten, die Anwendungen benötigen, im lokalen Cache befinden. Das Diagramm auf der rechten Seite zeigt einen Fall, in dem alle heißen und warmen Daten automatisch im Cache gespeichert werden, zusammen mit einigen kalten Daten und einigen angehefteten Daten. Insgesamt wird der größte Teil des lokalen Smart Cache-Speicherplatzes von aktiven Daten (hot+warm) verwendet. Die Menge der "Cold Pinned"-Dateien sollte immer überwacht werden, da dies auf eine Pinning-Regel hinweist, die nicht mehr relevant ist und möglicherweise nicht mehr benötigt wird. Diese Regeln sollten aus dem System entfernt werden.
Globale Dateisperrung und globale Dateikonsistenz in Echtzeit
Panzura ist das einzige globale Dateisystem mit Datenkonsistenz in Echtzeit über alle Standorte hinweg. Das heißt, dass jeder Benutzer, der eine Datei zur Bearbeitung öffnet, die zuletzt gespeicherten Änderungen sieht, unabhängig davon, wo diese Änderungen vorgenommen wurden. Unser patentiertes Dateisperrverfahren spielt bei diesem Prozess eine entscheidende Rolle. Die globale Dateisperre ist das Herzstück, das es geografisch verteilten Benutzern ermöglicht, zusammenzuarbeiten, ohne sich gegenseitig zu überschreiben oder mehrere Dateiversionen zu erstellen.
Dateneigentum, Datensperrung und Datenmobilität
CloudFS entkoppelt Daten und Metadaten physisch. Diese Entkopplung ermöglicht es dem Dateisystem, äußerst flexibel darauf zu verweisen, welche physischen Blöcke zum Aufbau einer Datei verwendet werden. Außerdem kann jeder Knoten im Dateisystem eine vollständige Kopie der Metadaten für das gesamte Dateisystem speichern, ohne die Dateien selbst speichern zu müssen.
PanzuraDas globale verteilte Dateisperren folgt drei einfachen Prinzipien.
- Wenn eine Datei erstellt wird, wird der Knoten, auf dem sie erstellt wurde, als Ursprung bezeichnet und in den Metadaten festgehalten.
- Origin weiß immer, welcher Knoten gerade die Sperre hat, unabhängig davon, ob die Datei gerade für die Bearbeitung gesperrt ist.
- Der Knoten mit der Sperre ist der Dateneigentümer, und diese Information ist in den Metadaten der Datei enthalten.
Der Dateneigentümerstatus wird über Metadaten-Snapshots transportiert. Ein Knoten, der die Dateneigentümerschaft für eine Datei übernehmen möchte, prüft seine Metadaten auf den Knoten, auf dem die Datei erstellt wurde (den Ursprung), und kommuniziert dann direkt mit dem Ursprung, um die Sperre anzufordern und der autorisierende Schreibknoten zu werden.
Wenn die Sperre beim Ursprung liegt, wird er die Anfrage entweder genehmigen oder ablehnen, wenn die Datei zur Bearbeitung geöffnet ist. Wenn der Ursprung derzeit nicht über die Sperre verfügt, teilt er dem anfragenden Knoten mit, von welchem Ort er sie anfordern soll.
Dateneigentumsanfragen und -übergänge sind häufige Ereignisse und werden in Echtzeit über kleine Peer-to-Peer-Kommunikation zwischen den Knoten ausgehandelt.
Der letzte Schritt nach einem Dateneigentümerwechsel besteht darin, sicherzustellen, dass der Benutzer, der die Datei jetzt öffnet, alle Änderungen sieht, die seit der letzten Synchronisierung mit dem Objektspeicher an der Datei vorgenommen wurden. Dies beinhaltet eine direkte Peer-to-Peer-Kommunikation zwischen dem Ursprung und dem neuen Dateneigentümer und möglicherweise dem aktuellen Dateneigentümer (der möglicherweise nicht der Ursprung ist).
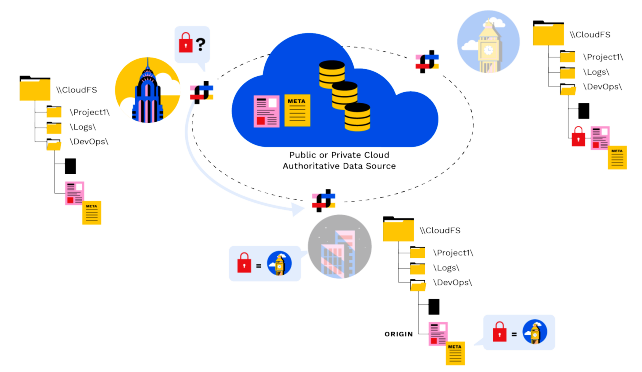
Innerhalb dieses Peer-to-Peer-Streams berechnen die Eigentümer-Metadaten eine endgültige Delta-Liste der Echtzeitänderungen, die seit dem Wechsel des Dateneigentümers stattgefunden haben könnten.
Diese Liste, die so klein wie ein einzelner Dateisystemblock sein kann, wird über einen sicheren, optimierten Datenkanal direkt an den neuen Dateneigentümer weitergeleitet. Der neue Dateneigentümer verarbeitet alle verbleibenden Deltas und macht die Datei aktuell und konsistent.
Alle Lese- und Schreibvorgänge von diesem Panzura System erfolgen nun als lokale E/A-Operationen auf dem neuen Dateneigentümer. Der Dateneigentümer behält die vollen Lese-/Schreibrechte, bis ein neuer Dateneigentümerwechsel stattfindet.
Globale Deduplizierung
Panzura’s interconnected global file system stops file-level duplication before data gets synced to the object store. Since only unique copies of files across all sites are preserved by the file system, data is deduplicated before it is ever stored.
Die Kapazität wird weiter optimiert, indem eine fortschrittliche Inline-Deduplizierung auf Blockebene für alle Daten im Objektspeicher durchgeführt wird, um Blöcke zu entfernen, die in verschiedenen Dateien vorkommen.
Im Gegensatz zu anderen Deduplizierungsanbietern bettet Panzura die Deduplizierungsreferenztabelle in die Metadaten ein, die sofort von allen Panzura Knoten gemeinsam genutzt werden. Diese Inline-Deduplizierungsmethode beseitigt die Datenredundanz über alle Knoten hinweg und nicht nur auf Basis der Daten, die von einem einzelnen Knoten gesehen werden. Auf diese Weise profitiert jeder Knoten im Netzwerk von den Daten, die alle anderen Knoten gesehen haben, was eine noch stärkere Kapazitätsreduzierung gewährleistet und sicherstellt, dass alle Daten in der Cloud eindeutig sind, wodurch die vom Unternehmen benötigte Cloud-Speicher- und Netzwerkkapazität (und die Kosten) gesenkt werden.
Unveränderliche Daten und Widerstandsfähigkeit gegenüber Ransomware
Die Hartnäckigkeit, die Verbreitung und der dokumentierte Erfolg von Ransomware-Angriffen deuten darauf hin, dass es selbst in gut ausgestatteten Unternehmen nicht möglich ist, eine vollständige Erstverteidigung aufzubauen. Deshalb ist es wichtig, dass kritische Geschäftsdaten so gut wie möglich geschützt sind. Das heißt, wenn Ihre Umgebung angegriffen wird und sogar darauf zugegriffen wird, werden die Daten selbst nicht fallen.
Das Herzstück eines jeden Ransomware-Angriffs ist die Fähigkeit, Dateien so zu verschlüsseln, dass sie ohne Zahlung eines Lösegelds an die Angreifer weder zugänglich noch wiederherstellbar sind. Panzura macht Daten für Ransomware unempfindlich, indem es sie in unveränderlicher Form speichert (Write Once, Read Many) und sie zusätzlich mit schreibgeschützten Snapshots schützt.
Mit Panzura können Daten, sobald sie sich im Cloud Object Store befinden, nicht mehr geändert, überschrieben oder in irgendeiner Weise beschädigt werden. Datei-Änderungen werden als neue Datenblöcke geschrieben, die keine Auswirkungen auf die vorhandenen Daten haben. Wenn neue Daten gespeichert werden, aktualisiert das globale Dateisystem von Panzuradie Dateizeiger, um aufzuzeichnen, aus welchen Datenblöcken eine Datei zu einem bestimmten Zeitpunkt besteht.
PanzuraDie leichtgewichtigen, schreibgeschützten Snapshots bieten dann eine granulare, zeitpunktbezogene Möglichkeit zur Wiederherstellung beliebiger Daten, indem sie aus dem jeweiligen Snapshot wiederhergestellt werden. Einzelne Dateien, Ordner oder sogar das gesamte Dateisystem können auf diese Weise wiederhergestellt werden.
Da sowohl die Snapshots als auch die Daten selbst unveränderlich sind, beschädigen Ransomware-Angriffe keine Dateien im globalen Dateisystem Panzura . Stattdessen werden Angriffe abgewehrt, indem schnell auf frühere Datenblöcke zurückgegriffen wird, um nicht infizierte Dateien wiederherzustellen.
Verschlüsselung nach Militärstandard und Einhaltung gesetzlicher Vorschriften
Panzura addresses data security concerns directly by applying military-grade encryption to all data stored in the cloud. Each Panzura node applies AES-256-CBC encryption for all data at rest in the object store. In addition, all data transmitted to or from the cloud is encrypted with TLS v1.2 while in flight, to prevent access via interception. Encryption keys are managed by the organization, never stored in the cloud. The solution is FIPS 140-2 certified.
Diese vollständige, robuste zweistufige Verschlüsselungslösung kommt zu der typischen mehrschichtigen Sicherheit hinzu, die von den gängigen Cloud-Speicheranbietern angeboten wird. In einigen Fällen stellen Unternehmen fest, dass die kombinierte Sicherheit einer Panzura+Cloud-Lösung größer ist, als sie in ihrer eigenen Infrastruktur vernünftigerweise erreichen können, was die Cloud-Speicherung sicherer macht als manche private Cloud-Implementierung.
Sicheres Löschen
Für IT-Umgebungen, die die Möglichkeit benötigen, alle Spuren hochsensibler Dateien sicher zu entfernen, ermöglicht CloudFS Secure Erase das Löschen einer Datei oder eines Ordners, so dass der Inhalt nicht wiederhergestellt werden kann, selbst unter Verwendung der modernsten verfügbaren Technologie.
CloudFS secure erase ist die höchste Bereinigungsstufe, die erreicht werden kann, ohne die Festplattenlaufwerke physisch zu zerstören. Dabei werden alle Versionen der angegebenen Dateien und Ordner vom Panzura -Knoten und den zugehörigen in der Cloud gespeicherten Objekten entfernt. Alle Daten werden sicher gelöscht und durch Nullen ersetzt. Secure Erase kann mit jedem unterstützten Cloud-Anbieter verwendet werden.
Cloud-Spiegelung
Mit der Cloud-Spiegelung können Sie die Verfügbarkeits-SLA eines einzelnen Cloud-Speicheranbieters effektiv verdoppeln und gleichzeitig einen unterbrechungsfreien Dienst im Falle eines Ausfalls eines Cloud-Speicherdienstes bereitstellen. Die Cloud-Spiegelung sorgt bei einem Ausfall des primären Anbieters automatisch für ein Failover zu einem redundanten Cloud-Speicheranbieter , ohne dass die Front-End-Dateidienste für Systeme oder Benutzer unterbrochen werden.
Dies ist nur möglich, weil die Cloud-Spiegelung für sofortige Datenkonsistenz sorgt.
Failover zum Zeitpunkt eines Ausfalls ist nicht möglich, wenn die Daten konsistent sind, was die meisten anderen Replikationsfunktionen bieten. Wenn der primäre Cloud-Objektspeicher wiederhergestellt ist, synchronisiert Panzura automatisch beide Clouds auf einen konsistenten Zustand - ohne menschliches Zutun. Außerdem sind Sie gegen versehentliches Löschen von Objekten oder Buckets geschützt.
Die Cloud Mirroring-Funktionalität löst das Problem des Auto-Failover im Falle eines Cloud-Ausfalls, bietet ein vollständiges Backup über die Replikation einer einzelnen Cloud hinaus und initiiert automatisch die Synchronisierung von Clouds nach einem Ausfall. Da Unternehmen zunehmend mehrere Clouds für die Speicherung nutzen, hilft die Cloud-Spiegelung, indem sie die Abhängigkeit von einem einzigen Anbieter beseitigt.
Suche, Prüfung und Sichtbarkeit des Dateinetzwerks
PanzuraDie leistungsstarke SaaS-Datenmanagementlösung Data Services bietet eine einzige, einheitliche Ansicht und Verwaltung unstrukturierter Daten, unabhängig davon, ob diese in der Cloud, vor Ort oder am Netzwerkrand gespeichert sind. Data Services nimmt den IT-Administratoren viele Stunden ihrer täglichen Arbeit ab und ist zudem ein wertvolles Tool für die schnelle Wiederherstellung nach Ransomware-Angriffen.
Globale Suche
Die beschleunigte globale Suche findet Dateien in Sekundenschnelle und durchsucht Ihr Panzura CloudFS und alle anderen angeschlossenen Knotenpunkte. Von den Suchergebnissen aus sind Audit- und Dateiwiederherstellungsoptionen mit einem Klick verfügbar.
Datei-Audit
Dateien können sowohl nach Benutzeraktion als auch nach Benutzer abgefragt werden. Mithilfe von Prüfaktionen wie dem Umbenennen von Dateien oder dem Festlegen von Dateiattributen kann die Suche nach potenziell datenschädigenden Aktionen, die möglicherweise Ransomware enthalten, eingegrenzt werden, während Aktionen wie Öffnen und Kopieren einen potenziell unbefugten Zugriff auf Daten aufzeigen können.
Klonen und Ersetzen
Kann beschädigte oder gelöschte Dateien in Sekundenschnelle in frühere Versionen und an frühere Speicherorte zurückversetzen.
Datei-Analytik
Speichermetriken auf einen Blick helfen Administratoren zu verstehen, was Speicherplatz verbraucht, wie sich die Speicheranforderungen ändern, worauf am häufigsten zugegriffen wird und welche Benutzer am aktivsten sind.
Dateisystem-Impuls
Überwachen Sie proaktiv den Zustand des Dateisystems, z. B. die CPU-Auslastung, Datenbewegungen, Cloud-Konnektivität und vieles mehr.
Globale Dienstleistungen und Kundenbetreuung
Panzura bietet Service und Support in jeder Phase der Implementierung von Panzura , von der Entwicklung und Erstellung der Lösung bis hin zum laufenden Betrieb und Support.
Der technische Support ist rund um die Uhr und 365 Tage in der Woche verfügbar, und mit den kosteneffizienten Support-Optionen können Sie das gewünschte Serviceniveau selbst bestimmen - vom schnellen reaktiven Support bis hin zum proaktiven und vorausschauenden Support, der dafür sorgt, dass unternehmenskritische Dienste mit maximaler Effizienz laufen.
Panzura hat einen branchenführenden NPS-Wert von 87.
ZUSAMMENFASSUNG
Das Ersetzen von Altspeichern durch einen modernen Ansatz für unstrukturierte Daten mit Hilfe von Cloud Object Storage bietet Unternehmen ein enormes Potenzial, um Speicherkosten zu senken, die Produktivität zu verbessern und das Risiko der Datenverfügbarkeit zu reduzieren.
Die vollständige und effektive Nutzung dieses Potenzials kann einen erheblichen Wettbewerbsvorteil bringen und gleichzeitig die geschäftlichen und technologischen Risiken verringern.
Panzura macht Unternehmen immun gegen Ransomware und ermöglicht eine schnelle Wiederherstellung im Falle eines Angriffs, wodurch Daten-, Zeit- und Produktivitätsverluste minimiert werden und kein Lösegeld gezahlt werden muss.
Der einzigartige geschäftliche Nutzen von Panzura umfasst:
Radikale Reduzierung der Knoten/Geräte und der Gesamtkomplexität
Panzura eliminiert mehrere Workloads und unterschiedliche Dateisysteme. Alle Lösungen werden von einem einzigen Anbieter geliefert, was die Supportkosten und das erforderliche interne Fachwissen senkt.
Integrierte Verringerung des aktuellen Risikoprofils um mehr als 75 %
Die unveränderliche Datenspeicherarchitektur und der replizierte Cloud-Objektspeicher machen zusätzliche BC/DR/Backup-Lösungen überflüssig und bieten gleichzeitig Schutz vor Ransomware, Verschlüsselung im Ruhezustand und Datenlebenszyklusmanagement.
Ein immerwährendes Produkt, das Ihren idealen zukünftigen Zustand ermöglicht
Die Software-definierte Lösung macht Hardware-Aktualisierungen und Migrationen überflüssig
und dient gleichzeitig als Transportschicht für das Objekt-Frontend, auf das Sie in Zukunft umsteigen werden.
Erschließung von Daten für Workloads der nächsten Generation als Wettbewerbsvorteil
Beschleunigen Sie die Wertschöpfung aus KI/ML/NLP mit Azure Cognitive Services oder anderen Cloud-APIs, indem Sie den vollständigen Datensatz überall verfügbar machen.
Erreichen echter Dateisysteme mit Zettabyte-Skalierung
Diese Architektur beseitigt viele der Engpässe herkömmlicher Dateisysteme, bei denen Objekte durch Inodes, Pfadnamen oder Adresszuweisungen eingeschränkt sind.