- Productos
- NUESTRA PLATAFORMA
 The Panzura Data Management PlatformModernice su infraestructura de almacenamiento de datos de archivos y mejore la seguridad.
The Panzura Data Management PlatformModernice su infraestructura de almacenamiento de datos de archivos y mejore la seguridad.
-
Discover why modern data leaders prefer the Panzura Data Management Platform
- NUESTROS PRODUCTOS Y OFERTAS
 Panzura CloudFSSimplifique y proteja su almacenamiento de datos con una única fuente autorizada.
Panzura CloudFSSimplifique y proteja su almacenamiento de datos con una única fuente autorizada. Panzura Detección y rescateAñada resistencia al ransomware con detección y alertas activas, y asistencia experta.
Panzura Detección y rescateAñada resistencia al ransomware con detección y alertas activas, y asistencia experta. Panzura Data ServicesObtenga visibilidad, gobernanza y análisis en un panel de control SaaS unificado.
Panzura Data ServicesObtenga visibilidad, gobernanza y análisis en un panel de control SaaS unificado. Panzura BordeMejore el acceso a los datos y potencie la colaboración con herramientas integradas.
Panzura BordeMejore el acceso a los datos y potencie la colaboración con herramientas integradas.
- Soluciones
- SOLUCIONES
- Banca, Servicios Financieros y SegurosAportar valor financiero impulsando la transformación digital
- Arquitectura, ingeniería y construcciónMejorar el tiempo de obtención de valor asegurando los datos y mejorando la colaboración entre sitios
- Sanidad y ciencias de la vidaProteger los datos de los pacientes, mejorar los resultados y potenciar la investigación
- Medios de comunicación y entretenimientoImpulsar la colaboración global segura y reducir el crecimiento exponencial de los datos
- FabricaciónRacionalización de los flujos de trabajo y mejora de la eficiencia para acelerar el tiempo de comercialización
- Sector públicoProporcionar seguridad de grado militar y permitir el cumplimiento avanzado de los datos
- Recursos
- Soporte
- ASISTENCIA AL CLIENTE
- Servicios GlobalesDisfrute de una migración de datos agilizada y de un servicio de atención al cliente de primera clase.
- Centro de serviciosUsted se merece el mejor servicio que el sector puede ofrecer. Consíguelo aquí.
- Base de conocimientosConozca todo lo que necesita saber sobre los productos y servicios de Panzura .
- Portal de sociosAcceda a herramientas y recursos diseñados exclusivamente para nuestros socios de canal.
- Información de apoyosoporte@panzura.com
- Acerca de
- ACERCA DE PANZURA
- Nuestra empresaHemos trazado un nuevo camino hacia la cima, ¡y es una historia increíble!
- Equipo directivoConozca a los inconformistas, los motivadores y las mentes maestras que impulsan nuestro éxito.
- CarrerasBuscamos a los mejores y más brillantes. Si eres tú, dínoslo.
- Sala de prensaManténgase al día con nuestras últimas noticias, conocimientos y actualizaciones de la empresa.
Libros blancos
Panzura CloudFS 8
CloudFS transforma entornos complejos, multicomponente y, a menudo, de múltiples proveedores en una solución simplificada de gestión de datos, al tiempo que aborda la reducción de costes, la mitigación de riesgos y la complejidad operativa.

El almacenamiento conectado a la red que ha sido el pilar del almacenamiento de datos durante casi 3 décadas está luchando para hacer frente a los crecientes volúmenes de almacenamiento. Tampoco es capaz de hacer que los archivos sean coherentes en todos los sitios en un plazo de tiempo que permita a los equipos ser productivos. El NAS ofrece un alto rendimiento cuando está situado cerca de los usuarios que acceden a los archivos que almacena, pero se vuelve increíblemente lento cuando los usuarios remotos intentan acceder a él.
Como resultado, las organizaciones despliegan instancias NAS individuales en cada ubicación, creando islas de almacenamiento desconectadas que contienen una cantidad significativa de duplicación de datos. Hacer que los archivos sean coherentes en todas las ubicaciones implica una replicación de datos programada, si es que se intenta, y los datos deben replicarse para lograr un nivel aceptable de durabilidad. Por lo general, esto significa al menos un conjunto secundario de datos para copias de seguridad y un conjunto terciario para la recuperación de desastres.
Esto contribuye al crecimiento exponencial de los datos no estructurados y genera complejidad y gastos para los equipos de TI, que luchan contra la falta de visibilidad de sus múltiples redes de archivos. Este enfoque heredado del almacenamiento de datos no permite restaurar fácilmente cantidades granulares de datos en caso de pérdida, y deja los datos expuestos a ransomware y otros ataques de malware.
CloudFS transforma entornos complejos, multicomponente y, a menudo, de múltiples proveedores en una solución simplificada de gestión de datos, al tiempo que aborda la reducción de costes, la mitigación de riesgos y la complejidad operativa.
Panzura's global cloud file system CloudFS provides a single authoritative data set held in cloud object storage, with immediate global data consistency and local-feeling file performance across all locations. Data from all legacy storage instances is consolidated, de-duped and compressed, significantly reducing the overall unstructured data footprint.
La compatibilidad con una amplia gama de almacenes de objetos proporciona la flexibilidad necesaria para consumir almacenamiento de nube pública, como AWS S3 y Azure Blob, o almacenamiento de objetos privado, como IBM iCOS y Cloudian.
Con la durabilidad de los datos sin replicación*, la capacidad granular de restaurar los datos a un punto en el tiempo y la resistencia frente al ransomware, la solución Panzura no sólo sustituye al almacenamiento conectado a la red, sino también a los procesos asociados de copia de seguridad y recuperación ante desastres externos y al almacenamiento. También ofrece un panel único de búsqueda y supervisión de toda la red de archivos.
Panzura CloudFS™
Panzura's global cloud file system CloudFS es un sistema de archivos distribuido que incorpora tecnología de aceleración de red, diseñado específicamente para acomodar almacenes de objetos remotos altamente latentes, y capaz de superar las limitaciones que impiden a las organizaciones integrar con éxito el almacenamiento en la nube en su infraestructura.
El resultado es una plataforma de servicios de archivos multi-nube que permite un alto rendimiento NAS por niveles, colaboración global de archivos, resistencia al ransomware, archivado activo, copia de seguridad y DR en todas las ubicaciones de una organización.
Almacenamiento basado en archivos
Panzura ha desarrollado una plataforma de almacenamiento global basada en archivos de alto rendimiento para la nube con el fin de abordar el 80% de los datos actuales que no están estructurados. Al ser compatible con los protocolos de transferencia NFS y SMB utilizados habitualmente por la mayoría de las aplicaciones, Panzura puede conectarse a las infraestructuras de TI existentes sin ningún cambio y conectarse a las principales plataformas de almacenamiento en la nube, lo que simplifica la implantación y minimiza el impacto en las operaciones. Todos los datos se gestionan bajo un único sistema de archivos global, lo que simplifica la interacción del usuario y la administración del sistema, al tiempo que se vincula a las aplicaciones de la organización y se dirige tanto al disco local como a la nube.
Almacenamiento de objetos en la nube
El almacenamiento de objetos, el típico sistema de almacenamiento utilizado en la nube, divide los datos y los almacena como contenedores o trozos de tamaño flexible. Cada trozo puede direccionarse individualmente, manipularse y almacenarse en muchas ubicaciones -no vinculadas a un disco concreto- con algunos metadatos asociados.
El almacenamiento de objetos puede escalar hasta miles de millones de objetos y exabytes de capacidad, al tiempo que protege los datos con mayor eficacia que RAID. Además, gracias a la arquitectura discreta de escalabilidad horizontal del almacenamiento de objetos, los fallos de las unidades apenas afectan a los datos y las funciones de replicación autorregenerables se recuperan muy rápidamente (piense en semanas para los sistemas RAID heredados de gran capacidad). Esta combinación de escala y robustez hace del almacenamiento de objetos un objetivo ideal para el almacenamiento de datos.
CloudFS interactúa directamente con las principales API de almacenamiento de objetos en la nube y los niveles de almacenamiento relacionados, y aprovecha el almacenamiento en la nube basado en objetos como almacén de datos para proporcionar escala y disponibilidad con una estructura de costes convincente.
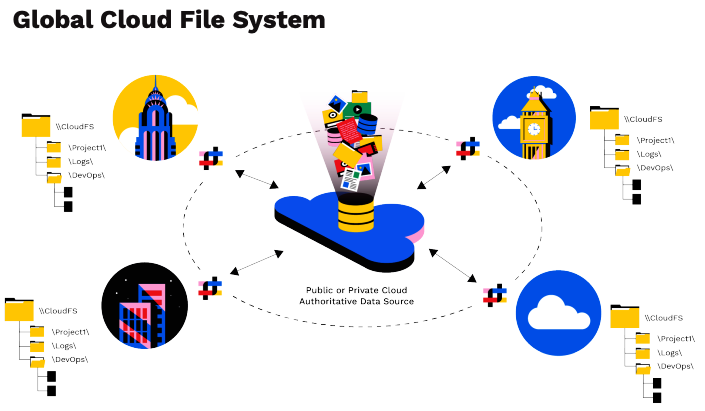
El corazón de cualquier sistema de almacenamiento de datos no estructurados es el sistema de archivos. Panzura CloudFS se diseñó para gestionar de cerca cómo se utilizan y almacenan los archivos con el fin de ofrecer una gestión de datos multicloud sólida, de alto rendimiento y sin fisuras. Mejora WAFL y ZFS al tiempo que integra el almacenamiento en la nube como una capacidad nativa. Cualquier usuario, en cualquier lugar, puede ver y acceder a los archivos creados por cualquier persona, en cualquier lugar y en cualquier momento.
El sistema de archivos coordina dinámicamente dónde se almacenan los archivos, qué se envía a la nube, quién tiene derechos de edición y acceso, qué archivos se almacenan localmente en caché para mejorar el rendimiento y cómo se gestionan los datos, los metadatos y las instantáneas. La estructura del sistema de archivos no tiene límite práctico para el número de instantáneas gestionadas por el usuario por CloudFS.
Panzura’s innovative use of metadata and snapshots for file system updates, combined with unique caching and pinning capabilities in the Panzura nodes—virtualized edge appliances deployed either locally or in the cloud—allows you to view data and interact through an enterprise-wide file system that is continually updated in real time. Support for extended file system access control lists (ACLs) empowers administrators to set file access and management policies on a per user basis.
Espacio de nombres global
The Panzura global namespace is an in-band file system fabric that integrates multiple physical file systems into a single space and is mounted locally on each node. The entire global namespace has the root label of the distributed cloud file system.
Como ejemplo, las siguientes 2 rutas de espacio de nombres globales apuntan al mismo directorio (\projects\team20) y son visibles desde ambos nodos, así como localmente en los nodos cc1-ln (Londres) y cc1-ny (Nueva York).
CloudFS está diseñado para garantizar la integridad inmediata de los datos en todos los sitios del sistema de archivos, independientemente del número de sitios y de la distancia entre ellos. Esto requiere la adhesión a dos principios fundamentales:
- Que sólo un usuario pueda editar el mismo archivo -o, cuando las aplicaciones admitan el bloqueo de rangos de bytes o elementos, la misma parte de un archivo- en cualquier momento. Si otro usuario intenta abrir un archivo, o acceder a parte de un archivo cuya edición está bloqueada, se le notificará que el archivo está bloqueado, o no podrá editar el elemento del archivo.
- Que cada vez que un usuario abra un archivo con acceso de lectura-escritura, verá las ediciones guardadas más recientes realizadas en ese archivo, independientemente de lo recientes que hayan sido esos cambios y de la ubicación del usuario que los haya realizado.
Para ello, Panzura disocia los datos de los metadatos e integra el espacio de nombres global en los metadatos.
Metadata is stored centrally in the cloud for durability in addition to being fully cached locally for enhanced performance. All nodes in a single namespace or CloudFS synchronize metadata updates simultaneously every 60 seconds in a hub (cloud) and spoke (node) configuration. This is further complemented by a peer to peer (mesh) synchronization event that occurs in real-time when lock dynamically moves from one node to another through the distributed global file locking.
Panzura Instantáneas para una coherencia global inmediata de los archivos
Instantáneas para mayor coherencia
Snapshots capture the state of a file system at a given point in time. For example, if blocks A, B, and C of a file are written and snapshot 1 is taken, that snapshot captures blocks A, B, and C to represent the file.
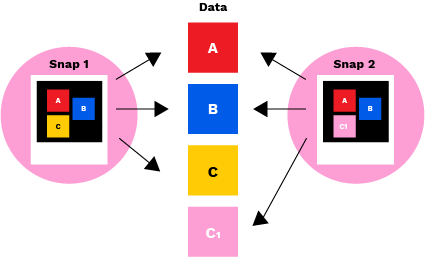
Si alguien edita el archivo de forma que el bloque C1 sustituya a C y se toma la instantánea 2, los punteros de datos en los bloques A, B y C del archivo de instantáneas apuntan ahora a A, B y C1. El bloque C aún se conserva, pero no se hace referencia a él en la instantánea 2. Si quisieras recuperar el estado original, puedes restaurar la instantánea 1, entonces el sistema volverá a apuntar a A, B y C, ignorando C1. Mediante el uso de instantáneas para crear y guardar una serie continua de puntos de recuperación para diferentes etapas en la vida de los datos, siempre se puede restaurar un estado consistente del sistema de archivos en caso de pérdida o daño de los datos.
Instantáneas de la moneda
Panzura utiliza las diferencias entre instantáneas consecutivas tanto para mantener la coherencia del sistema de archivos como para proteger los datos en el sistema de archivos. En un proceso denominado sincronización, el sistema de archivos Panzura toma los cambios netos de metadatos y datos entre instantáneas consecutivas y los envía a la nube. La parte de metadatos de estos cambios es recuperada de la nube por todos los demás nodos Panzura en el CloudFS configurado, donde se utilizan para actualizar el estado del sistema de archivos y mantener la vigencia (véase la imagen siguiente).
Esta actualización del sistema se produce de forma continua en todos los nodos, y cada uno de ellos envía y recibe deltas de instantáneas de metadatos extremadamente pequeños hacia y desde la nube en una configuración de hub y spoke, utilizándolos para actualizar el sistema de archivos de forma fluida y transparente.
Por ejemplo, un nodo en Londres (azul en la figura siguiente) toma la Snap 1 y más tarde toma la Snap 2. La diferencia de metadatos entre la instantánea 1 y la 2 de Londres se muestra en azul como 1-2Meta. La diferencia de datos entre Snap1 y Snap2 para Londres se muestra en azul como 1-2Data. Londres envía sus 1-2Meta y 1-2Data para actualizar la nube, al igual que el resto de nodos de la infraestructura. Londres también recibe actualizaciones de metadatos de todos los demás nodos (mostradas como 1-2Meta en rosa para Nueva York y en rojo para Las Vegas).
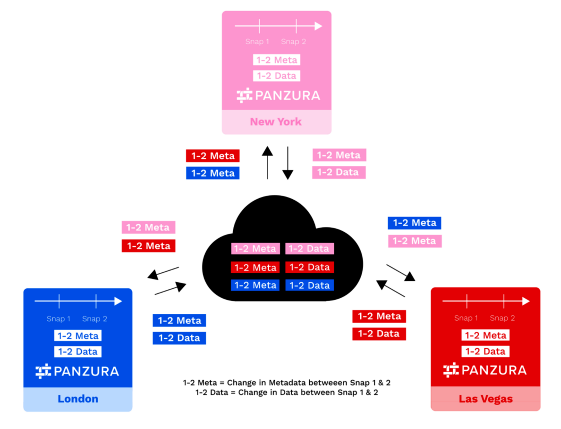
Todos los cambios en los datos y metadatos se almacenan y rastrean secuencialmente en el tiempo.
En caso de pérdida o corrupción de datos en el nodo local o en la nube, los datos pueden restaurarse a cualquier estado anterior en el que se haya tomado una instantánea, sin necesidad de seguir un proceso de copia de seguridad independiente.
Es importante reiterar que el tamaño de estos deltas de instantáneas (1-2Meta, 1-2Data) es excepcionalmente pequeño en relación con los datos del sistema de archivos; por tanto, pueden capturarse continuamente y utilizar el ancho de banda y la capacidad de forma muy eficiente.
El resultado es el Santo Grial de un sistema de archivos global: una solución que apenas requiere gastos generales y proporciona actualizaciones rápidas, continuas y casi en tiempo real en todos los sitios.
Instantáneas para la eficiencia
Panzura no tienen límite práctico para las instantáneas gestionadas por el usuario. Esta categoría de instantáneas permite a los usuarios recuperar datos sin intervención de TI, simplemente encontrando la instantánea deseada en su inventario y restaurándola. Las políticas en torno a las instantáneas gestionadas por el usuario (frecuencia, antigüedad, etc.) las define la administración de TI. Por ejemplo, un usuario de Microsoft Windows en Nueva York viaja a Londres y se da cuenta de que necesita un archivo que borró hace 3 meses. Dirige su Explorador de Windows al nodo local de Londres Panzura , navega a su carpeta de instantáneas y encuentra la fecha/hora que corresponde a la vista del sistema de archivos que contiene el archivo que quiere recuperar. Abre la instantánea, navega hasta el archivo o archivos que desea recuperar y, a continuación, arrastra y suelta el archivo o archivos necesarios en la ubicación actual del sistema de archivos en la que desea restaurarlos. En cuestión de minutos, habrá recuperado los archivos que necesita y podrá continuar con su trabajo, sin necesidad de que intervenga nadie del departamento de TI.
Para facilitar su uso, las instantáneas de usuario se han integrado con la función de versión anterior de Windows, lo que permite a los usuarios hacer clic con el botón derecho en cualquier archivo o carpeta y restaurar fácilmente a cualquier instantánea anterior. La administración de TI puede cambiar dinámicamente las políticas de instantáneas según sea necesario para satisfacer las políticas de retención de datos, equilibrar la frecuencia y la duración para un rendimiento óptimo del sistema y la satisfacción del usuario.
Instantáneas Ventajas
Panzura La tecnología de instantáneas proporciona tres ventajas principales para el sistema de archivos global: coherencia, actualidad y eficacia. Las instantáneas continuas proporcionan puntos de recuperación granulares para que, en caso de pérdida de datos, se pueda restaurar un estado coherente del sistema de archivos con la mínima interrupción o retraso.
Panzura La tecnología de instantáneas proporciona a todos los usuarios en todas las ubicaciones una vista actual de todo el sistema de archivos. Esto se consigue sincronizando todas las vistas del sistema de archivos globalmente en tiempo real, lo que permite a los usuarios experimentar el almacenamiento en la nube como si fuera local, resolviendo el principal inhibidor de un verdadero sistema de archivos global.
Al permitir a los usuarios recuperar sus propios datos cuando lo necesiten, la tecnología de instantáneas Panzura descarga un aspecto clave de la asistencia al usuario, liberando tiempo para proyectos estratégicos de TI. El nodo Panzura lleva la potencia de la nube a las organizaciones sin sacrificar la experiencia del usuario.
Almacenamiento en caché inteligente en la periferia para un rendimiento de sensación local
SmartCache
Panzura CloudFS utiliza un porcentaje definible por el usuario del almacenamiento local como SmartCache para realizar un seguimiento inteligente de las estructuras de bloques de archivos calientes, templados y fríos a medida que se accede a ellos. Esta forma de almacenamiento en caché aumenta drásticamente el rendimiento de E/S de las lecturas (y reduce los costes de acceso al almacenamiento de objetos en la nube), ya que las realiza desde el almacenamiento en caché local (tanto en memoria como en flash local persistente) en lugar de desde el almacenamiento externo en la nube. El sistema de archivos también amortigua las variaciones en la disponibilidad de la nube para ayudar a mantener tiempos de respuesta de lectura/escritura constantes: rendimiento Y disponibilidad en el límite.
Las políticas de almacenamiento en caché ofrecen dos funciones básicas. La primera función son los datos anclados, que mantienen los datos disponibles en el almacenamiento local utilizando reglas de política comodín flexibles. La fijación es una acción forzada y se ejecuta contra archivos completos, mientras que SmartCache es una acción estimulada por la lectura que se ejecuta contra bloques de un archivo a los que se accede con frecuencia.
Los datos anclados dan como resultado una garantía de lectura local del 100%, mientras que SmartCache es determinista y se basa en patrones de lectura de E/S anteriores dentro del nodo local. La segunda función proporcionada por las políticas de caché es Auto-Caching, que almacena automáticamente los datos en caché local basándose en reglas definidas. Sin embargo, los datos almacenados en caché automática pueden ser desalojados para los datos calientes solicitados, según sea necesario.
Los datos anclados, o en caché automática, son un subconjunto del nivel de almacenamiento total de SmartCache. Los datos anclados se consideran datos en caché de alta prioridad que nunca se desalojan a menos que lo autorice el administrador, mientras que los datos en caché automática (almacenados en caché en función de reglas comodín) o en caché SmartCache (bloques de datos almacenados en caché automáticamente en función de los patrones de uso observados) pueden ser desalojados por el sistema si es necesario para dejar espacio a los datos a los que se accede con más frecuencia. El equilibrio entre la fijación y SmartCache es delicado, ya que una regla de fijación obligará a que los bloques de datos se coloquen lógicamente dentro de SmartCache, consumiendo espacio local, lo que puede afectar a la utilización y eficiencia de la caché local de formas que el administrador puede no haber considerado. Debido a que las políticas de anclaje son de la más alta prioridad y anulan las reglas de almacenamiento en caché basadas en el comportamiento observado, se debe prestar especial atención a esas políticas para no consumir todo el almacenamiento local dejando poco para los datos calientes reales.
La función Auto Pre-populate proporciona un grado aún mayor de capacidades automatizadas de almacenamiento en caché. Si está activada, el nodo prealmacenará automáticamente los archivos en función de los cambios de propiedad entre los nodos de un CloudFS. Esto es particularmente útil en flujos de trabajo colaborativos en los que usuarios de diferentes sitios están trabajando en los mismos conjuntos de datos. A medida que el nodo detecta cambios de propiedad entre ubicaciones, automáticamente almacenará en caché los datos en el mismo directorio en previsión de las solicitudes de lectura de los usuarios sobre esos archivos entre sitios.
Uso del almacenamiento local
Una parte del almacenamiento local se asigna a SmartCache. Esta porción es configurable y está fijada en un 50% por defecto. Con el tiempo y el uso general, el sistema rellena dinámicamente la caché local con bloques de datos calientes de todos los archivos que leen los usuarios y las aplicaciones. La configuración más óptima y eficiente de SmartCache es tener la mayor parte de la caché compuesta por bloques calientes y templados, con la mayoría de los bloques fríos siendo desalojados a la nube. En este caso, un alto porcentaje de las lecturas se realizan directamente desde la caché local en lugar de desde la nube. Este es el estado óptimo de la caché, pero es más difícil de conseguir cuando se añaden más reglas de anclaje.
Los bloques que residen en la caché local se caracterizan por una combinación de 3 estados de temperatura diferentes, 2 estados de modificación y 2 estados de protección. Estos son:
Pinned-Los bloqueosque han sido pinned reciben la máxima prioridad en la SmartCache y son los últimos en ser desalojados, pero sólo si se necesita espacio de escritura crítico.
Bloqueos en calientea los que se accede con frecuencia para realizar lecturas (de 0 a 7 días).
El objetivo es tener la mayoría de los bloques calientes en la caché local.
Calientes: bloquesque han estado calientes recientemente pero que no han sido leídos tan recientemente como cualquiera de los bloques calientes (8-30 días). Se desalojarán después de los bloques fríos, pero antes de los calientes, si es necesario.
Se necesita espacio SmartCache.
Frío: bloquesa los que no se ha accedido en 30 días o más. Son los primeros bloques que se desalojan cuando SmartCache necesita espacio para bloques anclados, calientes o templados. En
siempre debe haber algunos bloques fríos, ya que esto indica que la SmartCache retiene completamente todos los bloques pinned, calientes y templados.
Modificados recientemente-Bloquesen los que se ha escrito como parte de las actualizaciones de un archivo.
No modificado: bloqueosque no se han escrito.
Protegido en la nube: bloquesque se han cargado correctamente en el almacenamiento en la nube.
Aún no protegidos en la nube-Bloqueosque están pendientes de subir a la nube.
El anclaje consume espacio de SmartCache forzando archivos completos a la caché local y está diseñado para que el administrador satisfaga las necesidades del usuario o del sitio anulando la lógica de auto-almacenamiento de SmartCache para desactivar el desalojo indefinidamente para bloques específicos.
Debido a esto, se debe prestar especial atención a las reglas específicas ancladas para evitar una regla que podría causar thrashing del espacio de caché local (desalojo rotativo de datos con nuevos datos debido a la reducción de la capacidad de la caché). Se recomienda que los administradores utilicen la acción Auto-Caching o habiliten la función Auto Pre-populate siempre que sea posible. Panzura CloudFS está diseñado para transferir todos los datos a la nube lo más rápidamente posible. Los datos siempre se consignan y se suben a la nube antes de que se calienten, se calienten o se enfríen en función de cualquier actividad de lectura reciente.
Cuando los datos están anclados, sólo se desalojan de SmartCache si el administrador cambia la política de anclaje o si se necesita espacio para escrituras y todos los demás datos calientes, templados y fríos han sido desalojados.
Los datos anclados se consideran datos de caché de alta prioridad. Por el contrario, los datos de SmartCache almacenados en caché automática se tratan como datos de caché de baja prioridad que el sistema puede desalojar automáticamente a medida que se necesita espacio de SmartCache para nuevos datos calientes. A medida que más datos anclados consumen el IRC, la capacidad utilizable de la caché automática se reduce. Esto afectará negativamente a los datos leídos con más frecuencia, haciendo que sean desalojados y luego vuelvan a ser leídos continuamente. Por lo tanto, las políticas agresivas que fijan grandes cantidades de datos deben utilizarse con moderación, ya que esto podría causar un exceso de E/S de disco local y reducir el rendimiento.
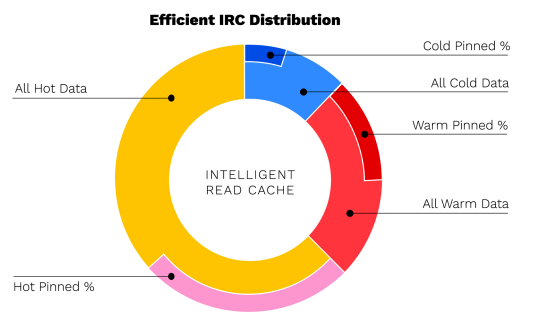
Lo ideal sería que la mayoría de los datos que necesitan las aplicaciones residieran en la caché local. El diagrama de la derecha muestra un caso en el que todos los datos calientes y templados se almacenan en caché con algunos datos fríos y algunos datos anclados. En general, la mayor parte del espacio del disco local de Smart Cache está siendo utilizado por datos activos (calientes+calientes). La cantidad de archivos fríos anclados siempre debe ser monitoreada ya que esto indica una regla de anclaje que ya no es relevante y potencialmente ya no es necesaria. Estas reglas deben eliminarse del sistema.
Bloqueo global de archivos y coherencia global de archivos en tiempo real
Panzura es el único sistema de archivos global con coherencia de datos en tiempo real en todos los sitios. Es decir, cualquier usuario que abra un archivo para editarlo verá los cambios guardados más recientes, independientemente de dónde se hayan realizado. Nuestro proceso patentado de bloqueo de archivos desempeña un papel crucial en este proceso. El bloqueo global de archivos es la clave para que los usuarios distribuidos geográficamente puedan trabajar en colaboración, sin sobrescribirse unos a otros ni crear múltiples versiones de los archivos.
Propiedad, bloqueo y movilidad de los datos
CloudFS desacopla físicamente los datos y los metadatos. Esta disociación permite al sistema de archivos ser muy flexible a la hora de referenciar qué bloques físicos se utilizan para construir un archivo. También permite que cada nodo del sistema de archivos contenga una copia completa de los metadatos de todo el sistema de archivos, sin tener que contener los propios archivos.
Panzurasigue tres sencillos principios.
- Cuando se crea un archivo, el nodo en el que se creó se designa como Origen, y esto se registra en sus metadatos.
- El Origen siempre sabe qué nodo tiene actualmente el bloqueo, independientemente de si el archivo está bloqueado para su edición.
- El nodo con el bloqueo es el propietario de los datos, y esta información se mantiene en los metadatos del archivo.
El estado del propietario de los datos se transporta a través de instantáneas de metadatos. Un nodo que desee asumir la Propiedad de los Datos de un archivo comprueba sus metadatos para el nodo en el que se creó el archivo (el Origen) y luego se comunica directamente con el Origen, para solicitar el bloqueo y convertirse en el Nodo Autoritario de Escritura.
Si el origen tiene el bloqueo, aprobará la solicitud o la denegará si el archivo está abierto para su edición. Si el origen no tiene el bloqueo, indicará al nodo solicitante en qué ubicación debe solicitarlo.
Las solicitudes de propiedad de datos y las transiciones son eventos frecuentes y se negocian en tiempo real a través de pequeñas comunicaciones peer-to-peer entre nodos.
El último paso tras una transición de propietario de datos es garantizar que el usuario que abra el archivo vea cualquier cambio que se haya realizado en el archivo desde la última sincronización con el almacén de objetos. Esto implica una comunicación directa peer-to-peer entre el Origen y el nuevo Propietario de Datos, y posiblemente el Propietario de Datos actual (que podría no ser el Origen).
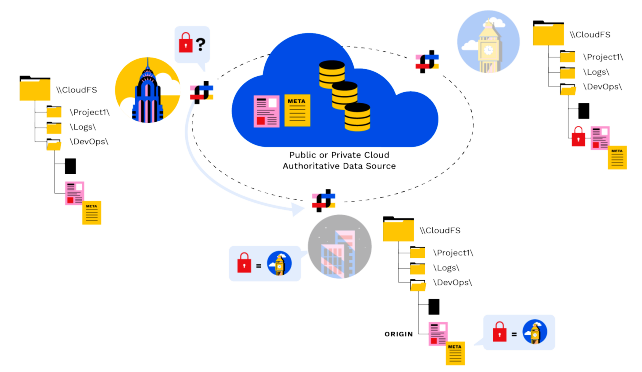
Dentro de este flujo entre pares, los metadatos de propiedad calculan una lista delta final de los cambios en tiempo real que pueden haberse producido desde que cambió el Propietario de los datos.
Esta lista, que puede ser tan pequeña como un solo bloque del sistema de archivos, se transmite directamente al nuevo propietario de los datos a través de un canal de datos seguro y optimizado. El nuevo propietario de los datos procesa todos los deltas restantes, con lo que el archivo queda actualizado y coherente.
Todas las lecturas y escrituras de archivos desde ese sistema Panzura se realizan ahora como operaciones locales de E/S en el nuevo propietario de datos. El propietario de los datos conserva la propiedad total de lectura/escritura hasta que se produzca una nueva transición de propietario de datos.
Deduplicación global
Panzura’s interconnected global file system stops file-level duplication before data gets synced to the object store. Since only unique copies of files across all sites are preserved by the file system, data is deduplicated before it is ever stored.
La capacidad se optimiza aún más ejecutando una deduplicación avanzada en línea a nivel de bloque en cualquier dato del almacén de objetos, con el fin de eliminar los bloques comunes a diferentes archivos.
A diferencia de cualquier otro proveedor de deduplicación, Panzura incorpora la tabla de referencia de deduplicación en los metadatos, que se comparten instantáneamente entre todos los nodos de Panzura . Este método de deduplicación en línea elimina la redundancia de datos en todos los nodos, en lugar de basarse únicamente en los datos vistos por un solo nodo. De este modo, cada nodo de la red se beneficia de los datos vistos por todos los demás nodos, lo que garantiza una reducción de la capacidad aún mayor, garantizando que todos los datos de la nube son únicos y reduciendo el almacenamiento en la nube y la capacidad de la red (y el coste) consumidos por la empresa.
Datos inmutables y resistencia al ransomware
La persistencia, la omnipresencia y el éxito documentado de los ataques de ransomware sugieren que puede que no sea posible montar una defensa completa de primera línea, incluso dentro de organizaciones con buenos recursos. Por eso es esencial que los datos críticos de la empresa sean lo más invulnerables posible. Es decir, si su entorno es atacado, e incluso se accede a él, los datos en sí no caerán.
El núcleo de todo ataque de ransomware es la capacidad de cifrar archivos de forma que no se pueda acceder a ellos ni recuperarlos sin pagar un rescate a los atacantes, a cambio de poder descifrarlos. Panzura hace que los datos sean inmunes al ransomware almacenándolos de forma inmutable (Write Once, Read Many) y protegiéndolos aún más con instantáneas de sólo lectura.
Con Panzura, una vez que los datos están en el almacén de objetos de la nube, no pueden ser modificados, sobrescritos o dañados de ninguna manera. Los cambios en los archivos se escriben como nuevos bloques de datos, que no afectan a los datos existentes. A medida que se guardan nuevos datos, el sistema de archivos global de Panzuraactualiza los punteros de los archivos para registrar qué bloques de datos componen un archivo en un momento dado.
PanzuraLas instantáneas ligeras y de sólo lectura proporcionan una capacidad granular y puntual para recuperar cualquier dato, restaurando a partir de la instantánea correspondiente. De este modo, se pueden restaurar archivos individuales, carpetas o incluso todo el sistema de archivos.
Dado que tanto las instantáneas como los propios datos son inmutables, los ataques de ransomware no dañan los archivos del sistema de archivos global Panzura . En lugar de ello, los ataques se libran de ellos volviendo rápidamente a los bloques de datos anteriores, para componer los archivos no infectados.
Cifrado de nivel militar y cumplimiento de la normativa
Panzura addresses data security concerns directly by applying military-grade encryption to all data stored in the cloud. Each Panzura node applies AES-256-CBC encryption for all data at rest in the object store. In addition, all data transmitted to or from the cloud is encrypted with TLS v1.2 while in flight, to prevent access via interception. Encryption keys are managed by the organization, never stored in the cloud. The solution is FIPS 140-2 certified.
Esta completa y robusta solución de cifrado a dos niveles se suma a la típica seguridad multicapa que ofrecen los principales proveedores de almacenamiento en la nube. En algunos casos, las empresas descubren que la seguridad combinada de una solución Panzura+nube es mayor de la que pueden alcanzar razonablemente dentro de su propia infraestructura, lo que hace que el almacenamiento en la nube sea más seguro que algunas implantaciones de nubes privadas.
Borrado seguro
Para entornos informáticos que requieren la capacidad de eliminar de forma segura todo rastro de archivos altamente sensibles, CloudFS Secure Erase permite eliminar un archivo o carpeta de forma que su contenido no pueda restaurarse, ni siquiera utilizando la tecnología más avanzada disponible.
El borrado seguro de CloudFS es el nivel de purga más alto que puede alcanzarse sin destruir físicamente las unidades de disco. Elimina todas las versiones de los archivos y carpetas especificados del nodo Panzura y los objetos asociados almacenados en la nube. Todos los datos se borran de forma segura y se sustituyen por ceros. El borrado seguro puede utilizarse con cualquier proveedor de nube compatible.
Replicación en la nube
Mediante la duplicación en la nube, puede duplicar de forma efectiva el SLA de disponibilidad de cualquier proveedor de almacenamiento en la nube y, al mismo tiempo, proporcionar un servicio ininterrumpido en caso de que se produzca un corte en el servicio de almacenamiento en la nube. La duplicación en la nube conmutará automáticamente a un proveedor de almacenamiento en la nube redundante en caso de fallo del proveedor principal sin interrumpir ningún servicio de archivos front-end para sistemas o usuarios.
Esto sólo es posible porque la duplicación en la nube proporciona una coherencia inmediata de los datos.
La conmutación por error en caso de fallo no es posible con una coherencia de datos eventual, que es lo que ofrecen la mayoría de las demás funciones de replicación. Cuando el almacén de objetos de la nube principal vuelva a funcionar, Panzura sincronizará automáticamente ambas nubes a un estado coherente, todo ello sin intervención humana. Además, estará protegido contra la eliminación accidental de objetos o cubos.
La función de duplicación en nube resuelve los problemas de recuperación automática en caso de fallo de la nube, proporciona una copia de seguridad completa más allá de la replicación en una sola nube e inicia automáticamente la sincronización de las nubes tras un fallo. Dado que las organizaciones emplean cada vez más varias nubes para el almacenamiento, la duplicación en la nube ayuda a eliminar la dependencia de un único proveedor.
Búsqueda, auditoría y visibilidad de la red de archivos
PanzuraLa potente solución SaaS de gestión de datos Data Services proporciona una visión y gestión únicas y unificadas de los datos no estructurados, ya estén almacenados en la nube, en las instalaciones o en el perímetro. Data Services elimina horas de la actividad diaria del administrador de TI, además de ser una valiosa herramienta para la recuperación rápida tras un ataque de ransomware.
Búsqueda global
La búsqueda global acelerada encuentra archivos en segundos, buscando en su Panzura CloudFS y en cualquier otro nodo conectado. Desde los resultados de la búsqueda, las opciones de auditoría y recuperación de archivos están disponibles con un solo clic.
Auditoría de archivos
Los archivos pueden consultarse por acción del usuario, así como por usuario. El uso de acciones de auditoría como el cambio de nombre de archivos o la configuración de atributos de archivos puede limitar la búsqueda para encontrar posibles acciones que dañen los datos y puedan contener ransomware, mientras que acciones como abrir y copiar pueden identificar posibles accesos no autorizados a los datos.
Clonar y sustituir
Puede revertir archivos dañados o eliminados a versiones anteriores, y a ubicaciones anteriores, en cuestión de segundos.
Análisis de archivos
Las métricas de almacenamiento de un vistazo ayudan a los administradores a comprender qué está consumiendo espacio, cómo están cambiando los requisitos de almacenamiento, a qué se accede con más frecuencia y qué usuarios son los más activos.
Pulso del sistema de archivos
Supervise de forma proactiva las métricas de estado del sistema de archivos, como el uso de la CPU, el movimiento de datos, la conectividad a la nube, etc.
Servicios globales y atención al cliente
Panzura ofrece servicio y asistencia en todas las fases de la implantación de Panzura , desde el diseño y la creación de la solución hasta las operaciones y la asistencia continuas.
La asistencia técnica está disponible 24 horas al día, 7 días a la semana, 365 días al año, y las opciones de asistencia rentables le permiten determinar el nivel de servicio que necesita, desde una asistencia reactiva rápida hasta una asistencia proactiva y predictiva diseñada para mantener los servicios de misión crítica funcionando con la máxima eficacia.
Panzura tiene una puntuación NPS de 87, líder del sector.
RESUMEN
La sustitución del almacenamiento heredado por un enfoque moderno de los datos no estructurados, mediante el almacenamiento de objetos en la nube, ofrece un enorme potencial a las organizaciones para reducir los costes de almacenamiento, mejorar la productividad y reducir el riesgo de disponibilidad de los datos.
Aprovechar ese potencial plena y eficazmente puede proporcionar una ventaja competitiva significativa, al tiempo que reduce tanto el riesgo empresarial como el tecnológico.
Fundamentalmente, Panzura dota a las organizaciones de inmunidad frente al ransomware, permitiendo una rápida recuperación en caso de ataque, minimizando la pérdida de datos, tiempo o productividad y eliminando la necesidad de pagar un rescate.
El valor empresarial único que ofrece Panzura incluye:
Reducción radical de nodos/aparatos y complejidad general
Panzura elimina múltiples cargas de trabajo y sistemas de archivos dispares. Todas las soluciones proceden de un único proveedor, lo que reduce los costes de asistencia y los conocimientos internos necesarios.
Reducciones incorporadas al perfil de riesgo actual de más del 75%.
La arquitectura de almacenamiento de datos inmutable y el almacenamiento de objetos replicado en la nube eliminan la necesidad de soluciones adicionales de BC/DR/Backup, a la vez que añaden protección contra ransomware, cifrado en reposo y gestión del ciclo de vida de los datos.
Producto perenne que permite su estado futuro ideal
La solución definida por software elimina las actualizaciones y migraciones de hardware
a la vez que sirve como la misma capa de transporte al front-end de objetos al que se traslade en el futuro.
Desbloquea datos para cargas de trabajo de nueva generación y obtener una ventaja competitiva
Acelere la obtención de valor a partir de IA/ML/NLP utilizando los servicios Azure Cognitive u otras API en la nube al disponer del conjunto de datos completo en cualquier lugar.
Logre verdaderos sistemas de archivos escalables a zettabytes
Esta arquitectura elimina muchos de los cuellos de botella de los sistemas de archivos tradicionales, en los que los objetos están limitados por inodos, nombres de ruta o asignación de direcciones.