- Produits
- NOTRE PLATEFORME
 The Panzura Data Management PlatformModernisez votre infrastructure de stockage de données et améliorez la sécurité.
The Panzura Data Management PlatformModernisez votre infrastructure de stockage de données et améliorez la sécurité.
-
Discover why modern data leaders prefer the Panzura Data Management Platform
- NOS PRODUITS ET OFFRES
 Panzura CloudFSSimplifiez et sécurisez le stockage de vos données grâce à une source unique faisant autorité.
Panzura CloudFSSimplifiez et sécurisez le stockage de vos données grâce à une source unique faisant autorité. Panzura Détection et sauvetageAjoutez une résilience aux ransomwares grâce à la détection active et aux alertes, ainsi qu'à l'assistance d'experts.
Panzura Détection et sauvetageAjoutez une résilience aux ransomwares grâce à la détection active et aux alertes, ainsi qu'à l'assistance d'experts. Panzura Data ServicesObtenez une visibilité, une gouvernance et des analyses dans un tableau de bord SaaS unifié.
Panzura Data ServicesObtenez une visibilité, une gouvernance et des analyses dans un tableau de bord SaaS unifié. Panzura BordAméliorez l'accès aux données et renforcez la collaboration grâce à des outils intégrés.
Panzura BordAméliorez l'accès aux données et renforcez la collaboration grâce à des outils intégrés.
- Solutions
- SOLUTIONS
- Banque, services financiers et assuranceCréer de la valeur financière en pilotant la transformation numérique
- Architecture, ingénierie et constructionAméliorer le délai de rentabilité en sécurisant les données et en renforçant la collaboration entre sites.
- Soins de santé et sciences de la vieProtéger les données des patients, améliorer les résultats et alimenter la recherche
- Médias et divertissementFavoriser une collaboration mondiale sécurisée et réduire la croissance exponentielle des données.
- FabricationRationalisation des flux de travail et amélioration de l'efficacité pour accélérer la mise sur le marché.
- Secteur publicFournir une sécurité de niveau militaire et permettre une conformité avancée des données.
- Ressources
- Soutien
- SUPPORT CLIENT
- Services mondiauxProfitez d'une migration des données simplifiée et d'un service clientèle de classe mondiale.
- Centre de servicesVous méritez le meilleur service que le secteur puisse offrir. Obtenez-le ici.
- Base de connaissancesDécouvrez tout ce que vous devez savoir sur les produits et services de Panzura .
- Portail des partenairesAccédez à des outils et des ressources conçus exclusivement pour nos partenaires de distribution.
- Informations sur le soutiensupport@panzura.com
- À propos de
- À PROPOS DE PANZURA
- Notre entrepriseNous avons tracé un nouveau chemin vers le sommet - et c'est une sacrée histoire !
- Équipe de directionRencontrez les francs-tireurs, les motivateurs et les cerveaux qui sont à l'origine de notre succès.
- CarrièresNous recherchons les meilleurs et les plus brillants. Si c'est vous, faites-le nous savoir.
- Salle de presseRestez au courant de nos dernières nouvelles, de nos points de vue et des mises à jour de l'entreprise.
Livres blancs
Panzura CloudFS 8
CloudFS transforme les environnements complexes, multicomposants et souvent multifournisseurs en une solution simplifiée de gestion des données, tout en réduisant les coûts, les risques et la complexité opérationnelle.

Le stockage en réseau (Network-Attached Storage), qui a été le pilier du stockage des données pendant près de trente ans, a du mal à faire face à l'escalade des volumes de stockage. Il est également incapable d'assurer la cohérence des fichiers d'un site à l'autre dans un délai permettant aux équipes d'être productives. Le NAS est très performant lorsqu'il est situé à proximité des utilisateurs qui accèdent aux fichiers qu'il stocke, mais il devient excessivement lent lorsque des utilisateurs distants tentent d'y accéder.
En conséquence, les entreprises déploient des instances NAS individuelles sur chaque site, créant ainsi des îlots de stockage déconnectés qui contiennent une quantité importante de données dupliquées. La cohérence des fichiers d'un site à l'autre implique une réplication programmée des données, si tant est qu'elle soit tentée, et les données doivent être répliquées pour atteindre un niveau de durabilité acceptable. En général, cela signifie qu'il faut au moins un ensemble secondaire de données pour la sauvegarde et un ensemble tertiaire pour la reprise après sinistre.
Cette situation contribue à la croissance exponentielle des données non structurées et engendre complexité et dépenses pour les équipes informatiques, qui se heurtent à un manque de visibilité sur leurs multiples réseaux de fichiers. Cette approche traditionnelle du stockage des données ne permet pas de restaurer facilement des quantités granulaires de données en cas de perte, et laisse les données exposées aux ransomwares et autres attaques de logiciels malveillants.
CloudFS transforme les environnements complexes, multicomposants et souvent multifournisseurs en une solution simplifiée de gestion des données, tout en réduisant les coûts, les risques et la complexité opérationnelle.
Panzura's global cloud file system CloudFS provides a single authoritative data set held in cloud object storage, with immediate global data consistency and local-feeling file performance across all locations. Data from all legacy storage instances is consolidated, de-duped and compressed, significantly reducing the overall unstructured data footprint.
La compatibilité avec un large éventail de magasins d'objets offre la possibilité d'utiliser le stockage en nuage public, comme AWS S3 et Azure Blob, ou le stockage d'objets privé, comme IBM iCOS et Cloudian.
Avec la durabilité des données sans réplication*, la capacité granulaire de restaurer les données à un point dans le temps et la résilience contre les ransomwares, la solution Panzura remplace non seulement le stockage en réseau, mais aussi les processus et le stockage de sauvegarde et de reprise après sinistre hors site qui y sont associés. Elle permet également la recherche et la surveillance de l'ensemble du réseau de fichiers à l'aide d'une seule fenêtre.
Panzura CloudFS™
PanzuraCloudFS est un système de fichiers distribués intégrant une technologie d'accélération du réseau, spécialement conçu pour accueillir des magasins d'objets distants à forte latence, et capable de surmonter les limites qui empêchent les organisations d'intégrer avec succès le stockage en nuage dans leur infrastructure.
Le résultat est une plateforme de services de fichiers multi-cloud qui permet des performances élevées en matière de NAS, une collaboration mondiale sur les fichiers, une résilience aux ransomwares, un archivage actif, une sauvegarde et une reprise après sinistre sur l'ensemble des sites d'une organisation.
Stockage basé sur des fichiers
Panzura a développé une plateforme de stockage globale basée sur des fichiers de haute performance pour le cloud afin de répondre aux 80 % de données actuelles qui ne sont pas structurées. En prenant en charge les protocoles de transfert NFS et SMB couramment utilisés par la plupart des applications, Panzura peut s'intégrer dans les infrastructures informatiques existantes sans aucun changement et se connecter à toutes les principales plateformes de stockage en nuage, ce qui simplifie le déploiement et minimise l'impact sur les opérations. Toutes les données sont gérées dans un seul système de fichiers global, ce qui simplifie l'interaction avec l'utilisateur et l'administration du système, tout en s'intégrant aux applications de l'entreprise et en ciblant à la fois le disque local et le nuage.
Stockage d'objets dans le nuage
Le stockage d'objets, le système de stockage typique utilisé dans l'informatique dématérialisée, décompose les données et les stocke sous forme de conteneurs ou de morceaux de taille flexible. Chaque morceau peut être adressé individuellement, manipulé et stocké à de nombreux endroits - sans être lié à un disque particulier - avec certaines métadonnées associées.
Le stockage d'objets peut évoluer vers des milliards d'objets et des exaoctets de capacité tout en protégeant les données de manière plus efficace que le RAID. En outre, en raison de l'architecture discrète du stockage d'objets, les défaillances des lecteurs ont peu d'impact sur les données et les fonctions de réplication à autoréparation se rétablissent très rapidement (quelques semaines pour les systèmes RAID traditionnels de grande capacité). Cette combinaison d'échelle et de robustesse fait du stockage objet une cible idéale pour les données d'entreposage.
CloudFS s'interface directement avec les principales API de stockage d'objets dans le nuage et les niveaux de stockage associés, et exploite le stockage d'objets dans le nuage comme un entrepôt de données pour fournir une échelle et une disponibilité avec une structure de coûts attrayante.
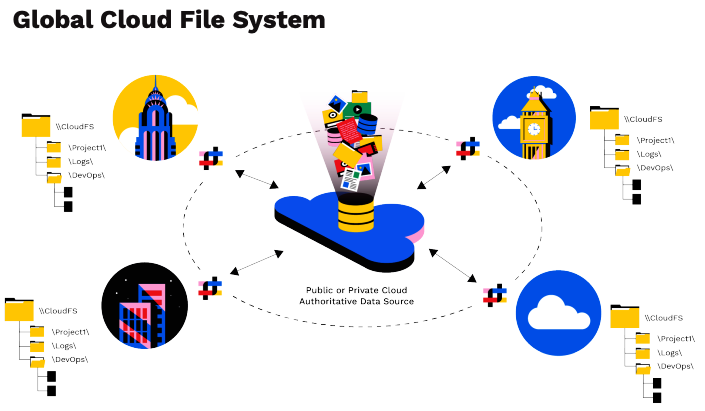
Le cœur de tout système de stockage de données non structurées est le système de fichiers. Panzura CloudFS a été conçu pour gérer étroitement la manière dont les fichiers sont utilisés et stockés afin de fournir une gestion des données multicloud transparente, performante et robuste. Il améliore WAFL et ZFS tout en intégrant le stockage en nuage en tant que capacité native. Tout utilisateur, où qu'il se trouve, peut consulter et accéder aux fichiers créés par n'importe qui, n'importe où et à n'importe quel moment.
Le système de fichiers coordonne dynamiquement l'endroit où les fichiers sont stockés, ce qui est envoyé dans le nuage, qui a les droits d'édition et d'accès, quels fichiers sont mis en cache localement pour améliorer les performances, et comment les données, les métadonnées et les instantanés sont gérés. La structure du système de fichiers n'impose aucune limite pratique au nombre d'instantanés gérés par l'utilisateur dans CloudFS.
Panzura’s innovative use of metadata and snapshots for file system updates, combined with unique caching and pinning capabilities in the Panzura nodes—virtualized edge appliances deployed either locally or in the cloud—allows you to view data and interact through an enterprise-wide file system that is continually updated in real time. Support for extended file system access control lists (ACLs) empowers administrators to set file access and management policies on a per user basis.
Espace de nom global
The Panzura global namespace is an in-band file system fabric that integrates multiple physical file systems into a single space and is mounted locally on each node. The entire global namespace has the root label of the distributed cloud file system.
Par exemple, les deux chemins d'espace de noms globaux suivants pointent vers le même répertoire (\projects\team20) et sont visibles depuis les deux nœuds ainsi que localement sur les nœuds cc1-ln (Londres) et cc1-ny (New York).
CloudFS est conçu pour garantir l'intégrité immédiate des données sur tous les sites du système de fichiers, indépendamment du nombre de sites et de la distance qui les sépare. Pour ce faire, deux principes fondamentaux doivent être respectés :
- Un seul utilisateur peut modifier le même fichier - ou, lorsque les applications prennent en charge le verrouillage par plage d'octets ou par élément, la même partie d'un fichier - à tout moment. Si un autre utilisateur tente d'ouvrir un fichier ou d'accéder à une partie d'un fichier dont l'édition est verrouillée, il sera averti que le fichier est verrouillé ou ne pourra pas modifier l'élément du fichier.
- Chaque fois qu'un utilisateur ouvre un fichier avec un accès en lecture-écriture, il voit les dernières modifications sauvegardées apportées à ce fichier, indépendamment de la date à laquelle ces modifications ont été effectuées et de l'emplacement de l'utilisateur qui les a effectuées.
Pour ce faire, Panzura dissocie les données des métadonnées et intègre l'espace de noms global dans les métadonnées.
Metadata is stored centrally in the cloud for durability in addition to being fully cached locally for enhanced performance. All nodes in a single namespace or CloudFS synchronize metadata updates simultaneously every 60 seconds in a hub (cloud) and spoke (node) configuration. This is further complemented by a peer to peer (mesh) synchronization event that occurs in real-time when lock dynamically moves from one node to another through the distributed global file locking.
Panzura Instantanés pour une cohérence globale immédiate des fichiers
Des instantanés pour plus de cohérence
Snapshots capture the state of a file system at a given point in time. For example, if blocks A, B, and C of a file are written and snapshot 1 is taken, that snapshot captures blocks A, B, and C to represent the file.
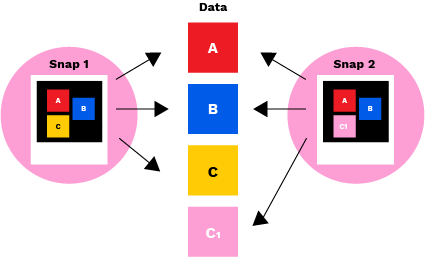
Si quelqu'un modifie ensuite le fichier de manière à ce que le bloc C1 remplace C et que l'instantané 2 est pris, les pointeurs de données dans les blocs A, B et C du fichier d'instantané pointent désormais vers A, B et C1. Le bloc C est toujours conservé mais n'est pas référencé dans l'instantané 2. Si vous souhaitez revenir à l'état d'origine, vous pouvez restaurer l'instantané 1. Le système pointera alors à nouveau sur A, B et C, sans tenir compte de C1. En utilisant les instantanés pour créer et sauvegarder une série continue de points de récupération à différentes étapes de la vie des données, il est toujours possible de restaurer un état cohérent du système de fichiers en cas de perte ou d'endommagement des données.
Instantanés pour la monnaie
Panzura utilise les différences entre les instantanés consécutifs à la fois pour maintenir la cohérence du système de fichiers et pour protéger les données dans le système de fichiers. Dans un processus appelé synchronisation, le système de fichiers Panzura prend les modifications nettes apportées aux métadonnées et aux données entre des instantanés consécutifs et les envoie au nuage. La partie métadonnées de ces changements est récupérée dans le nuage par tous les autres nœuds Panzura dans le CloudFS configuré, où ils sont utilisés pour mettre à jour l'état du système de fichiers et maintenir l'actualité (voir l'image ci-dessous).
Cette mise à jour du système s'effectue en continu sur tous les nœuds, chaque nœud envoyant et recevant des deltas d'instantanés de métadonnées extrêmement petits vers et depuis le nuage dans une configuration en étoile, et les utilisant pour mettre à jour le système de fichiers de manière transparente et transparente.
Par exemple, un nœud à Londres (en bleu dans la figure ci-dessous) prend l'instantané 1 et plus tard l'instantané 2. La différence de métadonnées entre l'instantané 1 et l'instantané 2 pour Londres est représentée en bleu par 1-2Meta. La différence de données entre l'instantané 1 et l'instantané 2 pour Londres est représentée en bleu par 1-2Data. London envoie ses 1-2Meta et 1-2Data pour mettre à jour le nuage, comme le font tous les autres nœuds de l'infrastructure. Londres reçoit également en retour les mises à jour des métadonnées de tous les autres nœuds (représentées par 1-2Meta en rose pour New York et en rouge pour Las Vegas).
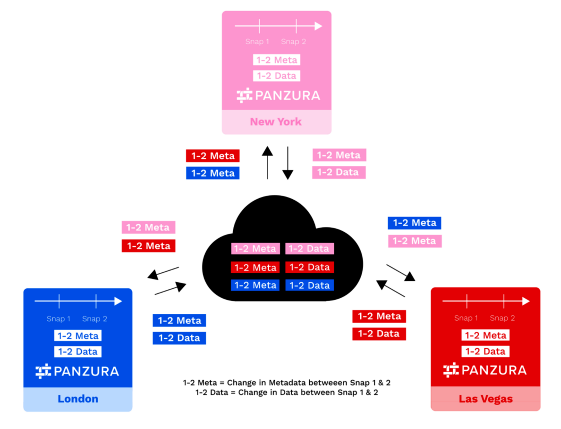
Toutes les modifications apportées aux données et aux métadonnées sont stockées et suivies séquentiellement dans le temps.
En cas de perte ou de corruption de données sur le nœud local ou dans le nuage, les données peuvent être restaurées à n'importe quel état antérieur auquel un instantané a été pris, sans qu'il soit nécessaire de suivre un processus de sauvegarde distinct.
Il est important de rappeler que la taille de ces deltas d'instantanés (1-2Meta, 1-2Data) est exceptionnellement petite par rapport aux données du système de fichiers ; ils peuvent donc être capturés en continu et utiliser la bande passante et la capacité de manière très efficace.
Le résultat est le Saint Graal d'un système de fichiers global : une solution qui ne nécessite pratiquement pas de frais généraux et qui permet des mises à jour rapides, continues et en temps quasi réel sur l'ensemble des sites.
Des instantanés pour plus d'efficacité
Panzura n'ont pas de limite pratique pour les instantanés gérés par l'utilisateur. Cette catégorie d'instantanés permet aux utilisateurs de récupérer des données sans intervention du service informatique, en trouvant simplement l'instantané souhaité dans leur inventaire et en le restaurant. Les politiques relatives aux instantanés gérés par l'utilisateur (fréquence, âge, etc.) sont définies par l'administration informatique. Par exemple, un utilisateur de Microsoft Windows à New York se rend à Londres et se rend compte qu'il a besoin d'un fichier qu'il a supprimé il y a trois mois. Il dirige son explorateur Windows vers le nœud local de Londres Panzura , navigue jusqu'à son dossier d'instantanés et trouve la date/heure correspondant à la vue du système de fichiers qui contient le fichier qu'il souhaite récupérer. Elle ouvre cet instantané et navigue jusqu'au(x) fichier(s) qu'elle doit récupérer, puis fait glisser le(s) fichier(s) nécessaire(s) vers l'emplacement actuel du système de fichiers où elle souhaite les restaurer. En quelques minutes, elle a récupéré tous les fichiers dont elle a besoin et peut poursuivre son travail, le tout sans l'intervention d'un informaticien.
Pour faciliter l'utilisation, les instantanés utilisateur ont été intégrés à la fonction Version précédente de Windows, ce qui permet aux utilisateurs de cliquer avec le bouton droit de la souris sur n'importe quel fichier ou dossier et de restaurer facilement n'importe quel instantané antérieur. L'administration informatique peut modifier dynamiquement les politiques d'instantanés en fonction des besoins pour satisfaire aux politiques de conservation des données, équilibrer la fréquence et la durée pour optimiser les performances du système et la satisfaction des utilisateurs.
Avantages de l'instantané
Panzura offre trois avantages majeurs au système de fichiers global : la cohérence, l'actualité et l'efficacité. Les instantanés continus fournissent des points de récupération granulaires de sorte qu'en cas de perte de données, un état cohérent du système de fichiers peut être restauré avec un minimum d'interruption ou de retard.
Panzura La technologie snapshot permet à tous les utilisateurs, où qu'ils se trouvent, d'avoir une vue actuelle de l'ensemble du système de fichiers. Pour ce faire, toutes les vues du système de fichiers sont synchronisées en temps réel au niveau mondial, ce qui permet aux utilisateurs de profiter du stockage en nuage comme s'il s'agissait d'un stockage local, éliminant ainsi le principal obstacle à un véritable système de fichiers global.
En permettant aux utilisateurs de récupérer leurs propres données en cas de besoin, la technologie Panzura snapshot décharge l'utilisateur d'un aspect essentiel de l'assistance, libérant ainsi du temps pour des projets informatiques stratégiques. Le nœud Panzura met la puissance du cloud à la disposition des entreprises sans sacrifier l'expérience de l'utilisateur.
Mise en cache intelligente à la périphérie pour une performance de proximité
SmartCache
Panzura CloudFS utilise un pourcentage du stockage local définissable par l'utilisateur comme SmartCache pour suivre intelligemment les structures de blocs de fichiers chauds, tièdes et froids au fur et à mesure de leur accès. Cette forme de mise en cache augmente considérablement les performances d'E/S des lectures (et réduit les frais d'accès au stockage d'objets dans le nuage) en les effectuant à partir du stockage local mis en cache (à la fois en mémoire et sur la mémoire flash locale persistante) plutôt qu'à partir d'un stockage externe dans le nuage. Le système de fichiers met également en mémoire tampon les variations de disponibilité du nuage pour aider à maintenir des temps de réponse de lecture/écriture cohérents - performance ET disponibilité à la périphérie.
Les politiques de mise en cache offrent deux fonctions de base. La première fonction est l'épinglage des données, qui permet de conserver les données disponibles sur le stockage local à l'aide de règles flexibles de type "wildcard". L'épinglage est une action forcée et exécutée sur des fichiers complets, tandis que SmartCache est une action stimulée par la lecture et exécutée sur des blocs fréquemment accédés dans un fichier.
Les données épinglées garantissent une lecture locale à 100 %, tandis que SmartCache est déterministe et s'appuie sur les schémas de lecture d'E/S précédents au sein du nœud local. La deuxième fonction fournie par les politiques de mise en cache est la mise en cache automatique qui met automatiquement en cache les données localement sur la base de règles définies. Toutefois, les données mises en cache automatiquement peuvent être expulsées pour les données chaudes demandées, selon les besoins.
Les données épinglées, ou mises en cache automatiquement, constituent un sous-ensemble de l'ensemble du niveau de stockage SmartCache. Les données épinglées sont considérées comme des données mises en cache de haute priorité qui ne sont jamais supprimées, sauf autorisation de l'administrateur, tandis que les données mises en cache automatiquement (mises en cache sur la base de règles de caractères génériques) ou SmartCache (blocs de données mis en cache automatiquement sur la base de modèles d'utilisation observés) peuvent être supprimées par le système en cas de besoin pour libérer de l'espace pour les données auxquelles on accède plus fréquemment. L'équilibre entre l'épinglage et SmartCache est délicat car une règle d'épinglage forcera les blocs de données à être logiquement placés dans SmartCache, consommant de l'espace local, ce qui peut affecter l'utilisation et l'efficacité du cache local d'une manière que l'administrateur n'a peut-être pas envisagée. Étant donné que les règles d'épinglage sont de la plus haute priorité et qu'elles remplacent les règles de mise en cache basées sur le comportement observé, il convient d'accorder une attention particulière à ces règles afin de ne pas consommer tout l'espace de stockage local et de ne pas en laisser trop pour les données chaudes.
La fonction de pré-remplissage automatique offre un degré encore plus élevé de capacités de mise en cache automatisée. Si elle est activée, le nœud pré-cache automatiquement les fichiers en fonction des changements de propriété entre les nœuds d'un CloudFS. Cette fonction est particulièrement utile dans les flux de travail collaboratifs où les utilisateurs de différents sites travaillent sur les mêmes ensembles de données. Lorsque le nœud détecte des changements de propriété entre les sites, il met automatiquement en cache les données dans le même répertoire en prévision des demandes de lecture des utilisateurs sur ces fichiers entre les sites.
Utilisation du stockage local
Une partie du stockage local est allouée à SmartCache. Cette portion est configurable et est fixée à 50 % par défaut. Au fil du temps et de l'utilisation générale, le système remplit dynamiquement le cache local avec des blocs de données chaudes provenant de tous les fichiers lus par les utilisateurs et les applications. La configuration SmartCache la plus optimale et la plus efficace consiste à faire en sorte que la majeure partie du cache soit constituée de blocs chauds et tièdes, la plupart des blocs froids étant expulsés vers le nuage. Dans ce cas, un pourcentage élevé de lectures est traité directement à partir du cache local plutôt qu'à partir du nuage. Il s'agit de l'état optimal de la mise en cache, mais il est plus difficile à atteindre lorsque davantage de règles d'épinglage sont ajoutées.
Les blocs résidant dans la mémoire cache locale sont caractérisés par une combinaison de 3 états de température différents, 2 états de modification et 2 états de protection. Ces états sont les suivants :
Épinglés - Les blocsqui ont été épinglés reçoivent la priorité la plus élevée dans le SmartCache et sont les derniers à être expulsés, mais seulement si un espace d'écriture critique est nécessaire.
Les Hot-Blockssont fréquemment accédés en lecture (de 0 à 7 jours).
L'objectif est d'avoir principalement des blocs chauds dans le cache local.
Warm - Blocsqui ont été récemment chauds mais qui n'ont pas été lus aussi récemment que les blocs chauds (8-30 jours). Ils seront expulsés après les blocs froids mais avant les blocs chauds s'ils sont en surnombre.
Un espace SmartCache est nécessaire.
Blocs froids : blocsqui n'ont pas été accédés depuis 30 jours ou plus. Ce sont les premiers blocs à être expulsés lorsque SmartCache a besoin d'espace pour des blocs épinglés, chauds ou tièdes. Il y a
doit toujours comporter des blocs froids, car cela indique que le SmartCache contient tous les blocs épinglés, chauds et tièdes.
Récemment modifiés - Blocsayant fait l'objet d'une écriture dans le cadre de la mise à jour d'un fichier.
Non modifié - Blocsqui n'ont pas été écrits.
Protégé dans le nuage - Blocsqui ont été téléchargés avec succès dans le nuage de stockage.
Pas encore protégé dans le nuage - Blocsen attente de téléchargement dans le nuage.
L'épinglage consomme de l'espace SmartCache en forçant des fichiers complets dans le cache local et est conçu pour que l'administrateur puisse satisfaire les besoins de l'utilisateur ou du site en remplaçant la logique de mise en cache automatique de SmartCache pour désactiver l'éviction indéfiniment pour des blocs spécifiques.
Pour cette raison, il convient d'accorder une attention particulière aux règles épinglées spécifiques afin d'éviter qu'une règle n'entraîne une saturation de l'espace de cache local (éviction tournante des données avec de nouvelles données en raison d'une capacité de cache réduite). Il est recommandé aux administrateurs d'utiliser l'action de mise en cache automatique ou d'activer la fonction de pré-remplissage automatique lorsque cela est possible. Panzura CloudFS est conçu pour transférer toutes les données dans le nuage aussi rapidement que possible. Les données sont toujours validées et téléchargées dans le nuage avant de devenir chaudes, tièdes ou froides en fonction de l'activité de lecture récente.
Lorsque des données sont épinglées, elles ne sont expulsées de SmartCache que si l'administrateur modifie la politique d'épinglage ou si de l'espace est nécessaire pour les écritures et si toutes les autres données chaudes, tièdes et froides ont été expulsées.
Les données épinglées sont considérées comme des données de cache à haute priorité. Inversement, les données SmartCache mises en cache automatiquement sont considérées comme des données de cache de faible priorité qui peuvent être expulsées automatiquement par le système lorsque l'espace SmartCache est nécessaire pour de nouvelles données chaudes. Au fur et à mesure que les données épinglées consomment l'IRC, la capacité utilisable de l'auto-cache est réduite. Cela aura un impact négatif sur les données les plus fréquemment lues, qui devront être expulsées puis relues en permanence. Par conséquent, les politiques agressives qui épinglent de grandes quantités de données doivent être utilisées avec parcimonie, car elles peuvent entraîner des E/S locales excessives sur le disque et réduire les performances.
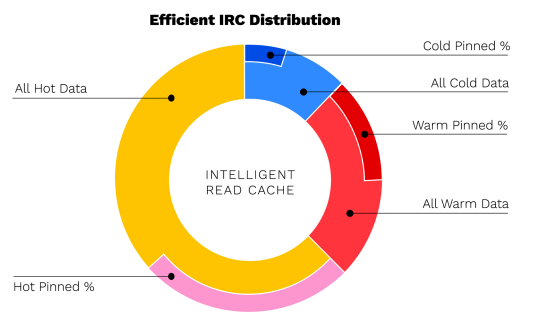
Idéalement, la plupart des données dont les applications ont besoin devraient résider dans le cache local. Le diagramme de droite illustre un cas où toutes les données chaudes et tièdes sont mises en cache automatiquement avec quelques données froides et quelques données épinglées. Globalement, la majeure partie de l'espace disque local du Smart Cache est utilisée par des données actives (chaudes+chaudes). La quantité de fichiers froids épinglés doit toujours être surveillée, car elle indique qu'une règle d'épinglage n'est plus pertinente et potentiellement plus nécessaire. Ces règles doivent être supprimées du système.
Verrouillage global des fichiers et cohérence globale des fichiers en temps réel
Panzura est le seul système de fichiers global dont les données sont cohérentes en temps réel sur tous les sites. En d'autres termes, tout utilisateur qui ouvre un fichier pour le modifier verra les dernières modifications enregistrées, quel que soit l'endroit où ces modifications ont été effectuées. Notre processus breveté de verrouillage des fichiers joue un rôle crucial dans ce processus. Le verrouillage global des fichiers est essentiel pour permettre aux utilisateurs géographiquement répartis de travailler en collaboration, sans s'écraser les uns les autres ni créer de multiples versions de fichiers.
Propriété des données, verrouillage des données et mobilité des données
CloudFS dissocie physiquement les données et les métadonnées. Ce découplage permet au système de fichiers d'être très flexible dans le référencement des blocs physiques utilisés pour construire un fichier. Il permet également à chaque nœud du système de fichiers de détenir une copie complète des métadonnées pour l'ensemble du système de fichiers, sans avoir à détenir les fichiers eux-mêmes.
PanzuraLe verrouillage des fichiers distribués à l'échelle mondiale suit trois principes simples.
- Lorsqu'un fichier est créé, le nœud sur lequel il a été créé est désigné comme étant l'origine, ce qui est enregistré dans ses métadonnées.
- L'origine sait toujours quel nœud détient le verrou, que le fichier soit ou non verrouillé pour l'édition.
- Le nœud avec le verrou est le propriétaire des données, et cette information est contenue dans les métadonnées du fichier.
L'état du propriétaire des données est transporté via des instantanés de métadonnées. Un nœud souhaitant devenir propriétaire des données d'un fichier vérifie dans ses métadonnées le nœud sur lequel le fichier a été créé (l'origine), puis communique directement avec l'origine pour demander le verrouillage et devenir le nœud d'écriture faisant autorité.
Si l'origine détient le verrou, elle approuve la demande ou la refuse si le fichier est ouvert à l'édition. Si l'origine ne détient pas actuellement le verrou, elle indique au nœud demandeur à quel endroit il doit le demander.
Les demandes de propriété de données et les transitions sont des événements fréquents et sont négociés en temps réel par le biais de petites communications de pair à pair entre les nœuds.
La dernière étape après le transfert du propriétaire des données consiste à s'assurer que l'utilisateur qui ouvre le fichier voit toutes les modifications qui ont été apportées au fichier depuis la dernière synchronisation avec le magasin d'objets. Cela implique une communication directe d'égal à égal entre l'origine et le nouveau propriétaire des données, et éventuellement le propriétaire actuel des données (qui peut ne pas être l'origine).
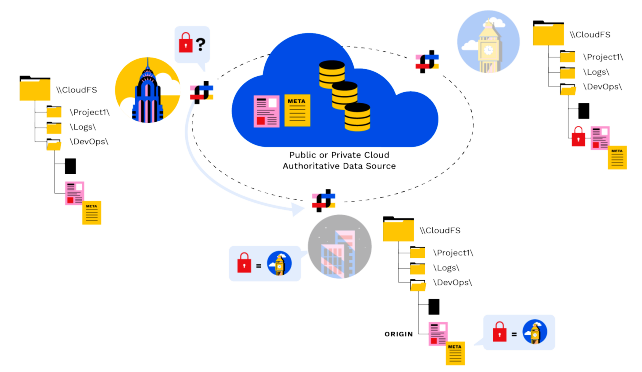
Dans ce flux pair à pair, les métadonnées de propriété établissent une liste delta finale des changements en temps réel qui ont pu se produire depuis que le propriétaire des données a changé.
Cette liste, qui peut être aussi petite qu'un seul bloc du système de fichiers, est transmise directement au nouveau propriétaire des données via un canal de données sécurisé et optimisé. Le nouveau propriétaire des données traite tous les deltas restants, ce qui rend le fichier actuel et cohérent.
Toutes les lectures et écritures de fichiers à partir de ce système Panzura se font maintenant comme des opérations d'E/S locales sur le nouveau propriétaire des données. Le propriétaire des données conserve la pleine propriété de la lecture et de l'écriture jusqu'à ce qu'une nouvelle transition de propriétaire de données se produise.
Déduplication globale
Panzura’s interconnected global file system stops file-level duplication before data gets synced to the object store. Since only unique copies of files across all sites are preserved by the file system, data is deduplicated before it is ever stored.
La capacité est encore optimisée par l'exécution d'une déduplication avancée en ligne au niveau des blocs sur toutes les données du magasin d'objets, afin de supprimer les blocs communs à différents fichiers.
Contrairement à tout autre fournisseur de déduplication, Panzura intègre la table de référence de déduplication dans les métadonnées, qui sont instantanément partagées entre tous les nœuds de Panzura . Cette méthode de déduplication en ligne supprime la redondance des données sur l'ensemble des nœuds, au lieu de se baser uniquement sur les données vues par un seul nœud. Ainsi, chaque nœud du réseau bénéficie des données vues par tous les autres nœuds, ce qui assure une réduction encore plus importante de la capacité, garantit que toutes les données dans le nuage sont uniques et réduit la capacité (et le coût) de stockage et de réseau du nuage consommée par l'entreprise.
Données immuables et résilience face aux ransomwares
La persistance, l'omniprésence et le succès avéré des attaques par ransomware semblent indiquer qu'il n'est peut-être pas possible de mettre en place une défense de première ligne complète, même au sein d'organisations disposant de ressources suffisantes. Il est donc essentiel que les données commerciales critiques soient aussi proches que possible de l'invulnérabilité. En d'autres termes, si votre environnement est attaqué, et même accédé, les données elles-mêmes ne tomberont pas.
Au cœur de chaque attaque de ransomware se trouve la capacité de chiffrer des fichiers de telle sorte qu'il est impossible d'y accéder ou de les récupérer sans payer une rançon aux attaquants, en échange de la possibilité de les déchiffrer. Panzura rend les données imperméables aux ransomwares en les stockant sous une forme immuable (Write Once, Read Many) et en les protégeant davantage grâce à des instantanés en lecture seule.
Avec Panzura, une fois que les données se trouvent dans le magasin d'objets en nuage, elles ne peuvent être ni modifiées, ni écrasées, ni endommagées de quelque manière que ce soit. Les modifications apportées aux fichiers sont écrites sous forme de nouveaux blocs de données, qui n'ont aucun effet sur les données existantes. Lorsque de nouvelles données sont enregistrées, le système de fichiers global de Panzuramet à jour les pointeurs de fichiers afin d'enregistrer les blocs de données qui composent un fichier à un moment donné.
PanzuraLes instantanés légers en lecture seule permettent ensuite de récupérer n'importe quelle donnée de façon granulaire et ponctuelle, en la restaurant à partir de l'instantané en question. Des fichiers individuels, des dossiers ou même l'ensemble du système de fichiers peuvent être restaurés de cette manière.
Étant donné que les instantanés et les données elles-mêmes sont immuables, les attaques de ransomware n'endommagent pas les fichiers du système de fichiers global Panzura . Au lieu de cela, les attaques sont contournées en revenant rapidement aux blocs de données précédents, pour reconstituer des fichiers non infectés.
Chiffrement de niveau militaire et conformité réglementaire
Panzura addresses data security concerns directly by applying military-grade encryption to all data stored in the cloud. Each Panzura node applies AES-256-CBC encryption for all data at rest in the object store. In addition, all data transmitted to or from the cloud is encrypted with TLS v1.2 while in flight, to prevent access via interception. Encryption keys are managed by the organization, never stored in the cloud. The solution is FIPS 140-2 certified.
Cette solution de cryptage complète et robuste à deux niveaux s'ajoute à la sécurité multicouche habituelle fournie par les principaux fournisseurs de services de stockage en nuage. Dans certains cas, les entreprises estiment que la sécurité combinée d'une solution Panzura+cloud est supérieure à celle qu'elles peuvent raisonnablement atteindre au sein de leur propre infrastructure, ce qui rend le stockage en nuage plus sûr que certains déploiements de nuages privés.
Effacement sécurisé
Pour les environnements informatiques qui nécessitent la possibilité de supprimer en toute sécurité toute trace de fichiers hautement sensibles, CloudFS Secure Erase permet de supprimer un fichier ou un dossier de manière à ce que son contenu ne puisse pas être restauré, même en utilisant la technologie la plus avancée disponible.
L'effacement sécurisé de CloudFS est le niveau de purge le plus élevé qui puisse être atteint sans détruire physiquement les disques. Il supprime toutes les versions des fichiers et dossiers spécifiés du nœud Panzura et des objets associés stockés dans le nuage. Toutes les données sont effacées en toute sécurité et remplacées par des zéros. Secure erase peut être utilisé avec n'importe quel fournisseur de cloud pris en charge.
Miroir du nuage
Grâce à la mise en miroir, vous pouvez effectivement doubler l'accord de niveau de service (SLA) de n'importe quel fournisseur de stockage en nuage, tout en fournissant un service ininterrompu en cas de panne du service de stockage en nuage. La mise en miroir du cloud bascule automatiquement vers un fournisseur de stockage redondant en cas de défaillance du fournisseur principal , sans perturber les services de fichiers frontaux pour les systèmes ou les utilisateurs.
Cela n'est possible que parce que l'écriture miroir dans le nuage assure une cohérence immédiate des données.
Le basculement au moment de la défaillance n'est pas possible avec une cohérence éventuelle des données, ce que proposent la plupart des autres fonctions de réplication. Lorsque le magasin d'objets du nuage principal est rétabli, Panzura synchronise automatiquement les deux nuages à un état cohérent, le tout sans intervention humaine. En outre, vous êtes protégé contre la suppression accidentelle d'un objet ou d'un panier.
La fonctionnalité de mise en miroir du nuage résout les problèmes de basculement automatique en cas de défaillance du nuage, fournit une sauvegarde complète au-delà de la réplication d'un seul nuage et lance automatiquement la synchronisation des nuages après une défaillance. Comme les entreprises utilisent de plus en plus souvent plusieurs nuages pour le stockage, la mise en miroir des nuages permet d'éliminer la dépendance à l'égard d'un seul fournisseur.
Recherche, audit et visibilité du réseau de fichiers
PanzuraLa puissante solution SaaS de gestion des données de Data Services offre une vue et une gestion uniques et unifiées des données non structurées, qu'elles soient stockées dans le nuage, dans les locaux ou à la périphérie. Data Services réduit le nombre d'heures de travail quotidien des administrateurs informatiques et constitue un outil précieux pour une récupération rapide en cas d'attaque de ransomware.
Recherche globale
La recherche globale accélérée permet de trouver des fichiers en quelques secondes, sur l'ensemble de votre Panzura CloudFS et sur tous les autres nœuds connectés. À partir des résultats de la recherche, les options d'audit et de récupération de fichiers sont disponibles en un seul clic.
Audit des dossiers
Les fichiers peuvent être interrogés par action de l'utilisateur, ainsi que par utilisateur. L'utilisation d'actions d'audit telles que le renommage de fichiers ou la définition d'attributs de fichiers permet d'affiner la recherche pour trouver des actions susceptibles d'endommager les données et de contenir des ransomwares, tandis que des actions telles que l'ouverture et la copie peuvent mettre en évidence un accès non autorisé potentiel aux données.
Cloner et remplacer
Permet de rétablir en quelques secondes les versions précédentes et les emplacements antérieurs des fichiers endommagés ou supprimés.
Analyse des fichiers
Les mesures de stockage en un coup d'œil aident les administrateurs à comprendre ce qui consomme de l'espace, comment les besoins de stockage évoluent, ce qui est le plus fréquemment consulté et quels sont les utilisateurs les plus actifs.
Impulsion sur le système de fichiers
Surveillez de manière proactive les mesures de santé du système de fichiers, telles que l'utilisation du processeur, le mouvement des données, la connectivité au cloud, etc.
Services globaux et assistance à la clientèle
Panzura fournit des services et une assistance à chaque étape du déploiement de Panzura , de la conception et de l'élaboration de la solution aux opérations et à l'assistance en cours.
L'assistance technique est disponible 24 heures sur 24, 7 jours sur 7 et 365 jours par an, et des options d'assistance rentables vous permettent de déterminer le niveau de service dont vous avez besoin, qu'il s'agisse d'une assistance réactive rapide ou d'une assistance proactive et prédictive conçue pour que les services critiques continuent à fonctionner avec une efficacité maximale.
Panzura a un score NPS de 87, le meilleur du secteur.
RÉSUMÉ
Remplacer le stockage traditionnel par une approche moderne des données non structurées, en utilisant le stockage d'objets dans le nuage, offre aux entreprises un énorme potentiel de réduction des coûts de stockage, d'amélioration de la productivité et de réduction des risques liés à la disponibilité des données.
L'exploitation complète et efficace de ce potentiel peut apporter un avantage concurrentiel significatif tout en réduisant les risques commerciaux et technologiques.
Le site Panzura confère aux organisations une immunité contre les ransomwares, permettant une récupération rapide en cas d'attaque, minimisant la perte de données, de temps ou de productivité et éliminant la nécessité de payer une rançon.
La valeur commerciale unique apportée par Panzura comprend
Réduction radicale des nœuds/appareils et de la complexité globale
Panzura élimine les charges de travail multiples et les systèmes de fichiers disparates. Toutes les solutions sont fournies par un seul fournisseur, ce qui réduit les coûts de support et l'expertise interne requise.
Réduction intégrée de plus de 75 % du profil de risque actuel
L'architecture de stockage de données immuables et le stockage d'objets répliqués dans le nuage éliminent le besoin de solutions BC/DR/Backup supplémentaires tout en ajoutant la protection contre les ransomwares, le cryptage au repos et la gestion du cycle de vie des données.
Produit évolutif qui permet d'atteindre l'état futur idéal
La solution définie par logiciel élimine les renouvellements et les migrations de matériel.
tout en servant de couche de transport pour l'interface objet vers laquelle vous vous dirigerez à l'avenir.
Débloque les données pour les charges de travail de nouvelle génération afin d'obtenir un avantage concurrentiel
Accélérez votre délai de rentabilisation de l'IA/ML/NLP à l'aide des services Azure Cognitive ou d'autres API cloud en disposant de l'ensemble des données partout.
Des systèmes de fichiers réellement évolutifs à l'échelle du zettaoctet
Cette architecture élimine de nombreux goulets d'étranglement des systèmes de fichiers traditionnels où les objets sont limités par des inodes, des noms de chemin ou l'allocation d'adresses.