- Productos
- NUESTRA PLATAFORMA
 The Panzura Data Management PlatformModernice su infraestructura de almacenamiento de datos de archivos y mejore la seguridad.
The Panzura Data Management PlatformModernice su infraestructura de almacenamiento de datos de archivos y mejore la seguridad.
-
Discover why modern data leaders prefer the Panzura Data Management Platform
- NUESTROS PRODUCTOS Y OFERTAS
 Panzura CloudFSSimplifique y proteja su almacenamiento de datos con una única fuente autorizada.
Panzura CloudFSSimplifique y proteja su almacenamiento de datos con una única fuente autorizada. Panzura Detección y rescateAñada resistencia al ransomware con detección y alertas activas, y asistencia experta.
Panzura Detección y rescateAñada resistencia al ransomware con detección y alertas activas, y asistencia experta. Panzura Data ServicesObtenga visibilidad, gobernanza y análisis en un panel de control SaaS unificado.
Panzura Data ServicesObtenga visibilidad, gobernanza y análisis en un panel de control SaaS unificado. Panzura BordeMejore el acceso a los datos y potencie la colaboración con herramientas integradas.
Panzura BordeMejore el acceso a los datos y potencie la colaboración con herramientas integradas.
- Soluciones
- SOLUCIONES
- Banca, Servicios Financieros y SegurosAportar valor financiero impulsando la transformación digital
- Arquitectura, ingeniería y construcciónMejorar el tiempo de obtención de valor asegurando los datos y mejorando la colaboración entre sitios
- Sanidad y ciencias de la vidaProteger los datos de los pacientes, mejorar los resultados y potenciar la investigación
- Medios de comunicación y entretenimientoImpulsar la colaboración global segura y reducir el crecimiento exponencial de los datos
- FabricaciónRacionalización de los flujos de trabajo y mejora de la eficiencia para acelerar el tiempo de comercialización
- Sector públicoProporcionar seguridad de grado militar y permitir el cumplimiento avanzado de los datos
- Recursos
- Soporte
- ASISTENCIA AL CLIENTE
- Servicios GlobalesDisfrute de una migración de datos agilizada y de un servicio de atención al cliente de primera clase.
- Centro de serviciosUsted se merece el mejor servicio que el sector puede ofrecer. Consíguelo aquí.
- Base de conocimientosConozca todo lo que necesita saber sobre los productos y servicios de Panzura .
- Portal de sociosAcceda a herramientas y recursos diseñados exclusivamente para nuestros socios de canal.
- Información de apoyosoporte@panzura.com
- Acerca de
- ACERCA DE PANZURA
- Nuestra empresaHemos trazado un nuevo camino hacia la cima, ¡y es una historia increíble!
- Equipo directivoConozca a los inconformistas, los motivadores y las mentes maestras que impulsan nuestro éxito.
- CarrerasBuscamos a los mejores y más brillantes. Si eres tú, dínoslo.
- Sala de prensaManténgase al día con nuestras últimas noticias, conocimientos y actualizaciones de la empresa.
Libros blancos
Manténgase al día, incluso cuando su almacenamiento primario se caiga.
Cloud Mirroring: La solución definitiva de alta disponibilidad para datos empresariales.

Cuando los datos son fundamentales para impulsar su organización, es primordial que sus archivos estén disponibles siempre que se necesiten, dondequiera que se necesiten, para cualquier usuario o proceso autorizado que los busque.
La redundancia dentro de su pila de TI es tan crítica como siempre lo ha sido, y como la experiencia ha demostrado, incluso los gigantes proveedores de almacenamiento en la nube pública pueden experimentar interrupciones. Por poco frecuentes que sean, su naturaleza disruptiva puede resultar excepcionalmente costosa.
La duplicación en nube de CloudFS le permite colocar el mismo conjunto de datos en dos almacenes de objetos separados, lo que le proporciona redundancia de datos con alta disponibilidad. Si su nube principal se cae, CloudFS cambia a su almacén de nube secundario, sin interrupción y sin pérdida de datos, lo que le permite continuar mientras su proveedor de nube principal está fuera de línea.
Conseguir almacenamiento en varias nubes y redundancia en las operaciones de archivo
Las soluciones modernas de almacenamiento en la nube para empresas suelen estar diseñadas para ofrecer altos niveles de durabilidad de los datos, con funciones como la replicación geográfica para que los datos sean resistentes a largo plazo. Sin embargo, las métricas de disponibilidad de datos suelen ser sustancialmente menos robustas, mientras que el impacto en los procesos de negocio que dependen de la disponibilidad inmediata de los datos es significativo cuando esos datos son inaccesibles.
Panzura cloud mirroring ofrece una alta disponibilidad de datos al mantener un conjunto de datos exactamente duplicados en un almacén de objetos secundario, lo que proporciona un servicio ininterrumpido en caso de interrupción del almacenamiento en la nube.
La 8ª generación del galardonado sistema global de archivos en la nube CloudFS™ de Panzuraintroduce la capacidad de duplicar datos en dos almacenes de objetos separados, escribiendo en ambos simultáneamente en tiempo real. Con la duplicación en la nube activada, puede utilizar un almacén de objetos primario y otro secundario, ambos con un conjunto de datos idéntico en todo momento. Una división de escritura en tiempo real captura los datos nuevos y modificados en ambos almacenes de objetos, a medida que se crean nuevos archivos o se realizan ediciones.
Si su almacén primario en la nube sufre una interrupción, CloudFS conmutará automáticamente al almacén secundario, permitiendo que los servicios de archivos frontales para sistemas o usuarios sigan funcionando. Cuando el almacén primario de objetos en la nube vuelva a estar disponible y vuelva a fallar, Panzura sincronizará automáticamente ambas nubes con un conjunto de datos coherente.
La duplicación en la nube no sólo elimina su dependencia de un único proveedor de almacenamiento en la nube o de objetos, sino que esta solución multicloud le protege frente a interrupciones y pérdidas de datos derivadas de la eliminación accidental de cubos en la nube, así como frente a ciberamenazas contra su proveedor de servicios en la nube.
CloudFS garantiza que ambos almacenes en la nube sean completamente coherentes, manteniendo exactamente el mismo conjunto de datos hasta el último byte, en todo momento. En caso de que necesite conmutar por error al almacén secundario, todos y cada uno de los archivos estarán allí, accesibles para todos los usuarios autorizados.
Cloud Mirroring en funcionamiento
CloudFS utiliza un conector de nube para comunicarse con cualquier almacén de objetos compatible a través de la API RESTful de esa nube. Este almacén de objetos puede ser una nube pública, una nube privada (en las instalaciones) o una nube completamente "oscura" sin conexión externa.
Dos almacenes de objetos compatibles con CloudFS pueden ser designados como nube primaria y secundaria. Pueden ser dos regiones de nube separadas del mismo proveedor, dos niveles de datos del mismo proveedor o dos almacenes de objetos distintos de proveedores no relacionados. Normalmente, el almacén de objetos secundario tiene un coste menor que el primario. Cada almacén tiene su propio conector de nube independiente.
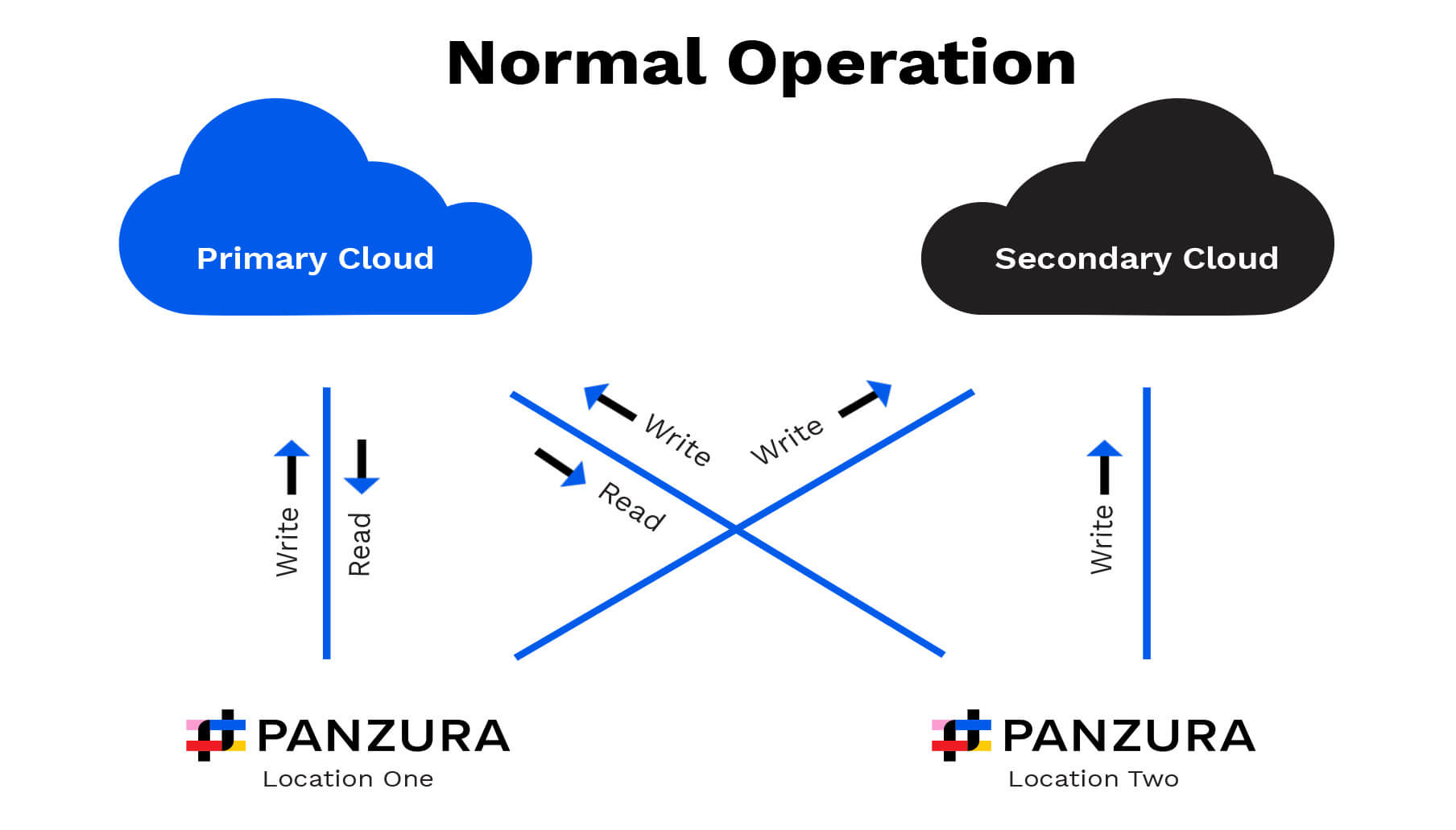
Cada ubicación de una red de archivos CloudFS lee de la nube primaria en tiempo real, anticipando y almacenando en caché los archivos más utilizados localmente para obtener un alto rendimiento.
Cada 60 segundos, cada ubicación de la red CloudFS escribe simultáneamente los datos nuevos y modificados tanto en la nube primaria como en la secundaria, almacenándolos como datos inmutables. Esta división de la escritura garantiza la captura de una copia completa y redundante de cualquier dato adicional en la nube secundaria, así como su almacenamiento seguro en la nube primaria y su disponibilidad en todas las demás ubicaciones para garantizar la coherencia inmediata de los datos.
Este diagrama ilustra un CloudFS de dos ubicaciones en funcionamiento normal, con la duplicación de nubes activada. Cada ubicación lee y escribe en la nube primaria, y escribe en la nube secundaria en paralelo.
Fallo y conmutación por error de la nube
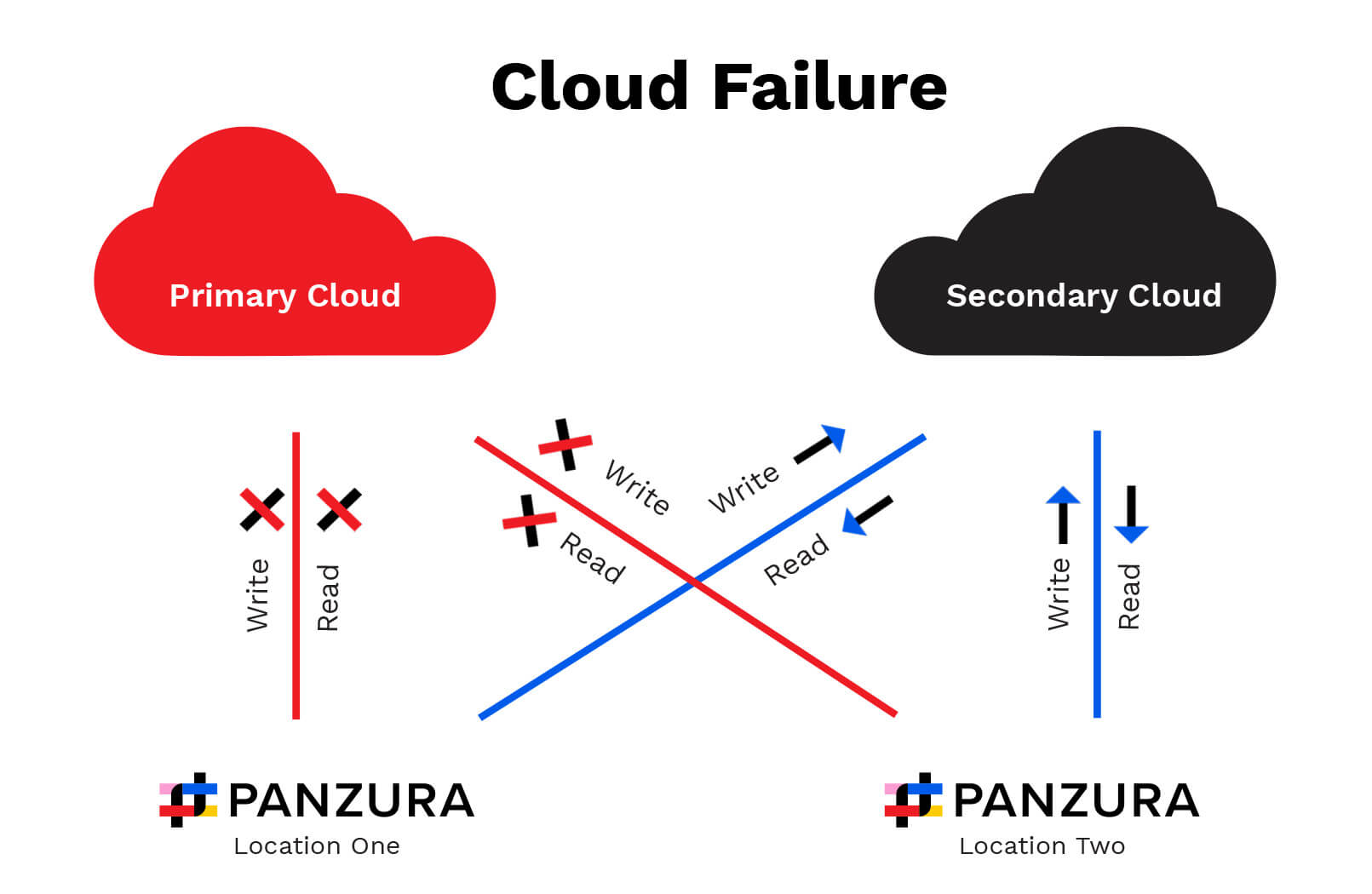
En caso de fallo de una nube, las operaciones de lectura y escritura en la nube que ha fallado se desactivan. Con la duplicación de nube activada, una interrupción sostenida de la nube principal hará que CloudFS pase a la nube secundaria para las operaciones de lectura y escritura, hasta que se restablezca la nube principal.
Dado que cada ubicación escribe en ambas nubes simultáneamente, los datos almacenados en la nube secundaria son completamente coherentes con los datos de la nube primaria, lo que se traduce en una experiencia fluida sin pérdida de datos ni incoherencias en los archivos, incluso en caso de fallo catastrófico del almacenamiento en la nube.
CloudFS no depende de la nube para ninguna operación de archivos. Como resultado, un fallo en la nube no afecta a funciones como el bloqueo de archivos o la coherencia inmediata de datos entre ubicaciones.
Como se muestra a continuación, mientras la nube primaria no está disponible, todas las ubicaciones de CloudFS leen y escriben en la nube secundaria. Esto permite que las operaciones de archivo continúen sin interrupciones, al tiempo que se mantiene un registro de los datos creados localmente que no se han sincronizado con la nube primaria.
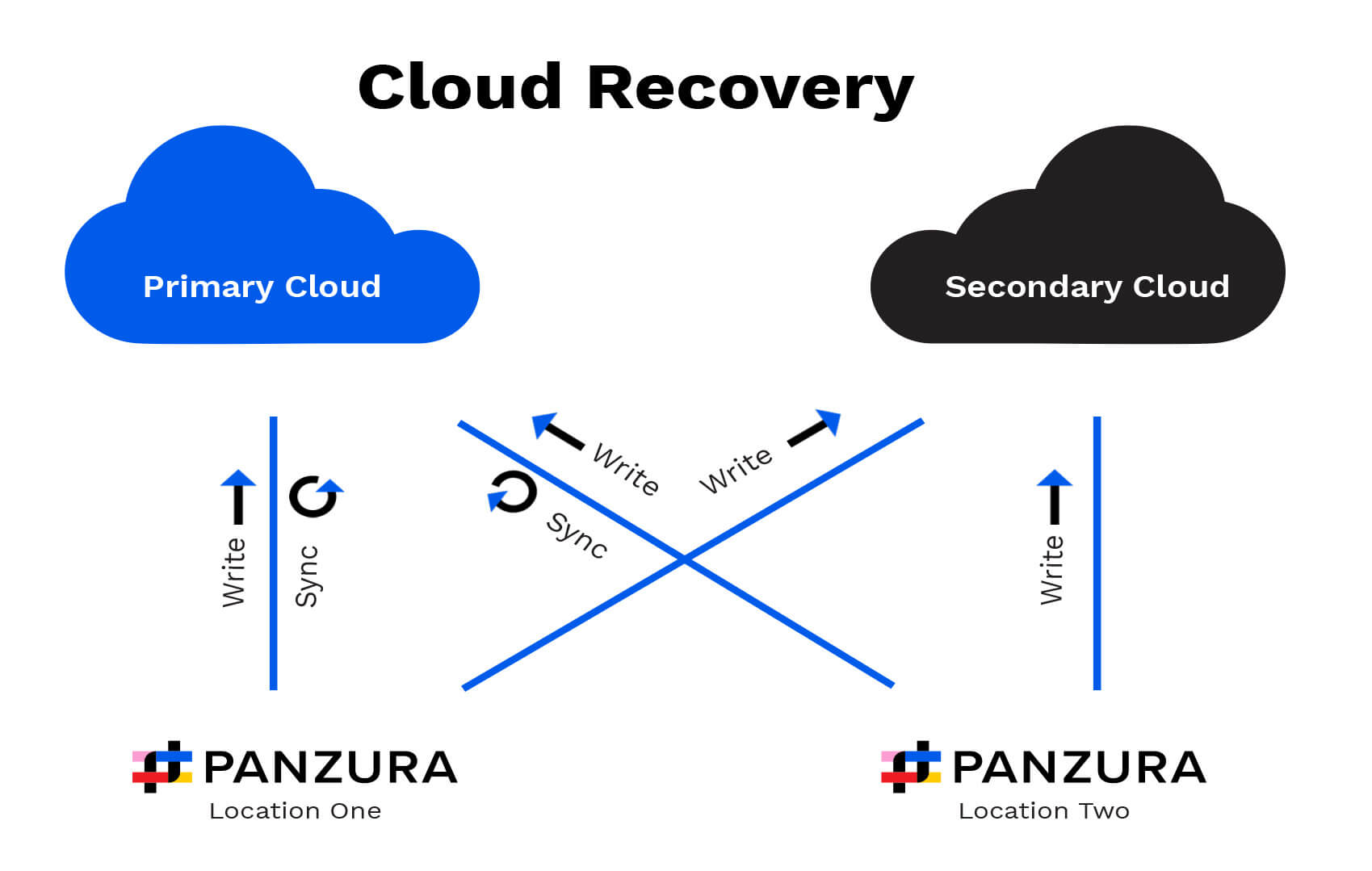
Cuando la nube principal vuelva a estar disponible, CloudFS reanudará la escritura en ambas nubes en paralelo, y un administrador puede volver a cambiar las operaciones de lectura a la nube principal, una vez que esté seguro de que es estable.
En segundo plano, CloudFS recurrirá entonces a los datos almacenados localmente y en la nube secundaria, incorporando todos los cambios realizados mientras no estaba disponible, para que la nube primaria sea coherente.
Más allá de las interrupciones del almacenamiento en la nube pública para mejorar la recuperación en caso de catástrofe
Los sonados cortes de suministro de gigantes del almacenamiento en la nube como AWS, Azure y Google han aumentado la concienciación sobre la necesidad de disponibilidad de los datos para las organizaciones que utilizan almacenamiento de objetos en la nube pública, garantizando que el propio almacenamiento de objetos no sea un único punto de fallo.
Si bien las interrupciones de servicio pueden ser relativamente breves cuando se deben a factores que están bajo el control del proveedor de la nube, no puede decirse lo mismo cuando esos proveedores de almacenamiento se convierten en el blanco de la acción intencionada de agentes malintencionados.
Además de la capacidad de conmutación por error inmediata en caso de interrupción del almacenamiento primario, la duplicación en la nube le ofrece una mayor durabilidad y resistencia de los datos con protección contra ransomware en caso de que su proveedor de almacenamiento primario sufra un ataque de malware o ransomware fuera de su control o del de Panzura.
Su almacén secundario en espejo proporciona una copia de seguridad en tiempo real con redundancia de datos actualizada en caso de que necesite cambiar de proveedor de almacenamiento durante un tiempo. Y lo que es más importante, en caso de desastre total, proporciona capacidades de recuperación acelerada, al mantener un conjunto de datos redundantes capaces de restauración granular sin pérdida de datos.
Es una capa crítica de la protección de datos en la nube
El valor que ahora tienen sus datos hace imprescindible que estén seguros, protegidos, duraderos y disponibles siempre que se necesiten.
Con la duplicación en la nube, puede proporcionar una alta disponibilidad con conmutación por error automática en el nivel del almacén en la nube elegido, protegiéndose contra las interrupciones en la nube, los ciberataques realizados directamente contra los proveedores de almacenamiento en la nube, la eliminación de cubos en la nube y otros eventos de almacenamiento de datos potencialmente catastróficos.
Cloud mirroring está disponible con CloudFS 8.1.0.